pointer浅挖
前言
指针和数组还有很多知识点需要学习
正文
sizeof(数组)
大部分情况下,我们使用sizeof(),编译器都是需要一个运行过程的。
而我们反汇编sizeof求数组大小的时候会发现不一样的点:
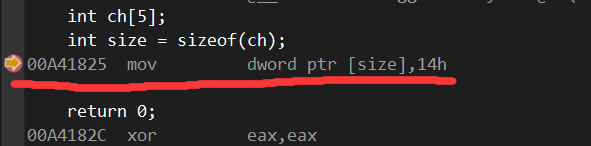
能看到反汇编后
1 | int main(){ |
头两句只有一句反汇编代码,首先也是因为数组没有初始化。
其次就是他调用数组大小是20,编译器仿佛知道这个数组的大小了,14h也就是十六进制的写法,换算成十进制也就是20,数组有五个成员*4正好就是20。
也就是之前说的,数组的底层实现是由指针实现的,数组本身是抽象的结构逻辑
所以编译器会提前预览出数组的大小,以便后续使用。
引用
引用是一种阉割的指针版本。
虽然取址引用变量得到的是原值的内存地址,但是引用的变量本身也占用内存。
1 | int a = 5; |
反汇编后看到: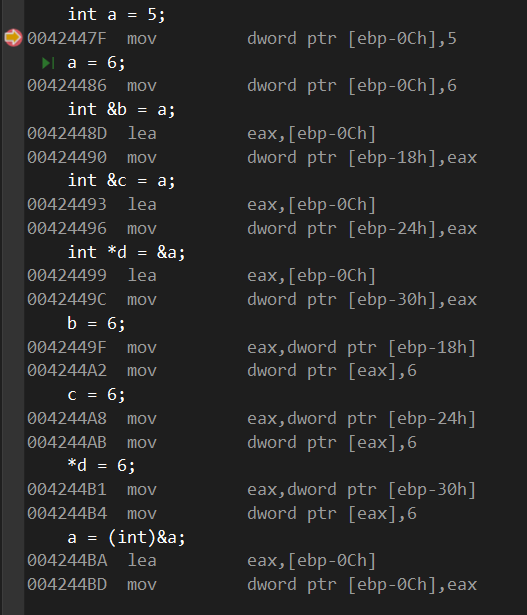
- a的地址就是ebp-Ch
- b的地址是ebp-18
在代码里我们看到&b=a之前,先将a的地址赋予eax,然后再将eax赋予b的地址上
这就说明了引用变量确实占用了内存。 - c的地址就是ebp-24
- d的地址就是ebp-30
- b=6的时候,先将b的地址的值赋给eax,引用b的地址在上述操作中为a的地址
- c=6和*d=6 发现步骤相同,区别就在于各自的内存地址不一样。不过也印证引用和指针的关联性。
堆和栈
空间分配:
- 栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
- 堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS(操作系统)回收,分配方式倒是类似于链表。
百度而来的浅显答案。
1 | int a; |
得到结果: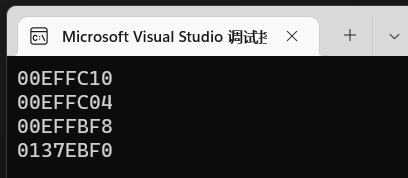
可以看到abc三个变量的地址离得很近,但是d却很远,d现在打印的地址是new出来的,我们捎上变量d本身的地址。
1 | std::cout << &a << std::endl; |
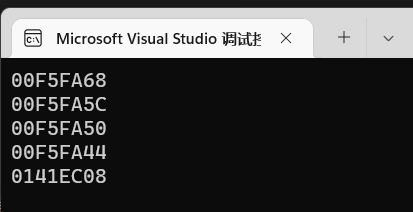
能看到d变量本身占用的内存地址里abc都是比较近的,因为他们都是挨着声明的,内存地址由计算机分配而来,也就是说这些变量的内存地址存放在栈区。
而new出来的那块内存则符合定义中由人为分配的,处于堆区。
栈区是程序在编译时就确定了大小的一段内存区域,主要用于存放临时变量,其效率也会高于堆,但是因为事先就确定了大小,导致了容量有限的问题,当然可以在编译前指定栈的大小,不过涉及到的东西有点多
另外就是栈比较有意思的是,他的结构是自上向下的结构,遵循先入后出顺序。
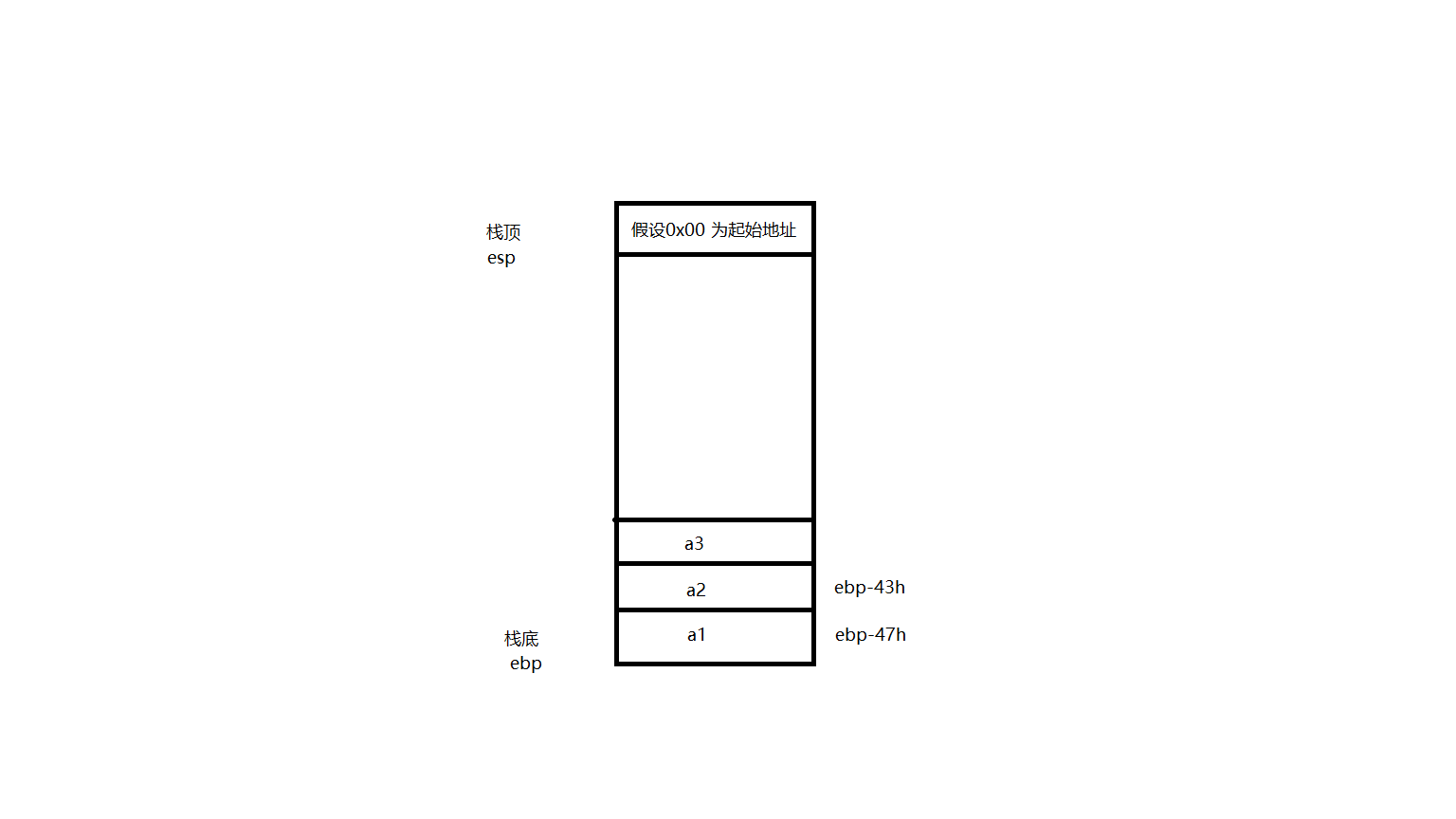
随便画张草图理解一下。
ebp通过地址减去得到变量的地址。当变量的声明周期全部结束了的时候,ebp的地址就会和esp一样了
结语
主要是浅看指针和数组和引用的关系,然后就是顺便理解堆栈的概念,因为反汇编多次出现了,总要先looklook。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Box'Blog!
相关推荐




评论