string
引用
- [] = “”
属于c语言的方式
前言
C语言是没有string类型的,那么要表示字符串就是通过char[]来实现。
声明方式就是char ch[] = "hello";
复古机器人点就是char ch[] = {'H','E','L','L','O','\0'};,当然鬼才用这个。
指针也ok,不过需要强转,因为默认不认识字符串char *ch = (char*)"hello";
但是要注意字符串末尾其实跟了一个\0作为结束,因为数组的本质是一块连续的内存空间,它需要区分。
有印象的应该知道,strlen和sizeof一个字符串的区别。
正文
假设有一个数字char str[255] {"Hello张三"};,编码环境为gbk
它的内存分析为:
张在gbk中需要两个字节来表示,所以原本应该是0xc5d5,但是由于是char类型,排放顺序从低位到高位,所以说先存d5再存c5。
c/wchar_t
宽字符:一般占用两个字节。即H 在内存中表现为0x0048,依然按照低位在前高位在后的顺序排放。

1 | wchar_t ch1[] = { "hello world" }; //直接声明就报错了 |

原因是默认的字符串还是以char为组合,需要向编译器声明是宽字符型
1 | wchar_t ch1[] = { L"hello world" }; |
也就是在字符串前加一个大写的L。
注意:宽字符一般采用Unicode编码,所以中文在Unicode和gbk的表现是不一样的
输入采用wscanf,输出采用wprintf,类型前加大写L转换。
1 | wchar_t ch[0xff]; |
如果scanf报错,在头文件上加一句#define _CRT_SECURE_NO_WARNINGS
当然这里还是值得一提的,为什么vs使用scanf会报错,这是因为scanf如果不限定长度,那么就有可能导致溢出,一旦溢出了,你往里面塞的如果是一些计算机相关的命令,就有可能被执行。所以vs推荐使用scanf_s,但是对于新手来说_s还是有点小麻烦的。
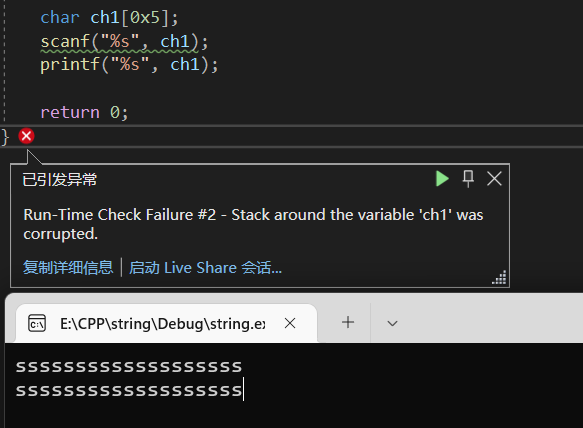
举个例子,字符串设置长度5,但是你输入了一堆,编译器这里肯定会发生异常报错。
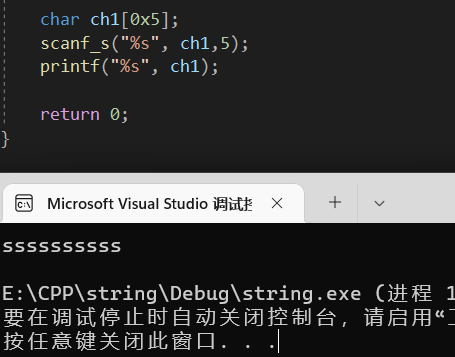
使用微软的_s,则相对安全,一旦你输入的内容长度超过了它限定的范围,那么程序就不接收你输入的东西。
不过有一说一,还有gets之类的输入方式,scanf是相对而言比较多的使用。所以不能防范所有的溢出问题。
cpp/wchar_t
c++的输入输出是通过cin/cout来实现,虽然可以使用C语言的方式,但是还是要记住c++本身的特性。
1 | int main(){ |
正常情况下,x没有赋值,就相当于是指针,那么cout x就是输出x的地址
但是char不一样,cout默认会将其当为字符串输出,就会导致乱码。
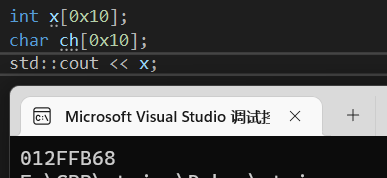
两者之间的区别还是很明显的
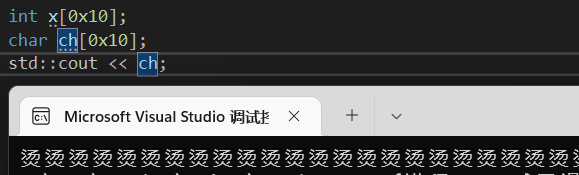
当然std指定输出格式也凑合,比较printf就是通过指定格式化输出实现。
1 | wchar_t ch[0xff]; |
差别不大,就是宽字符的输入输出都加个w,然后注意一下编码环境
wcslen
统计字符串都知道使用strlen,宽字符也有自己的统计函数wcslen
1 |
|
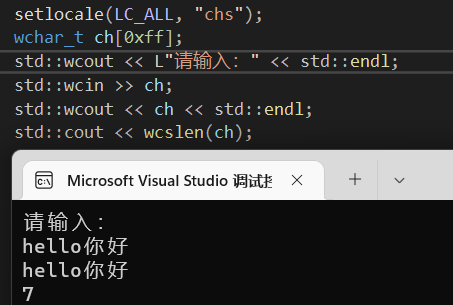
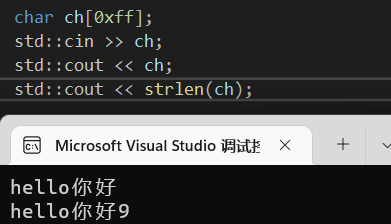
值得一提的是,宽字符在指定编码下一般都是两个字节为一个字符,所以对于统计中英文时,会相对而言方便,但是内存上占用高了些,而char需要两个字节统计一个中文
自己实现strlen
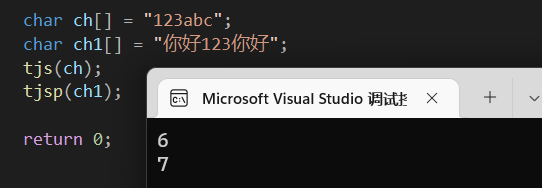
其实也不难,我们知道字符串以’\0’结尾,那就直接循环然后让一个变量自增直到’\0’结束就行了
1 | void tjs(char *ch){ |
传一个指针,因为数组本质上就是一个指针,所以问题不大。
自制能统计带中文的字符串
1 | void tjsp(char *ch){ |
其实一开始想的是中文需要两个char类型接受,然后一个char的上限是0xff,然后突然想到中文在两个char下其实两边都不一定会到0xff。
那好就从ascii码入手,
可以看到ascii上限是0x7f,那如果*ch大于0x7f也就是说他有可能就是中文字符。。。
但是好景不长,结果还是不对,然后我就打断点debug了一下,发现它读取字符串的时候,遇到中文都是转换成了负数。。。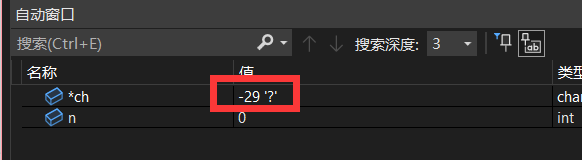
这个原理我还没搞明白,但是这么一搞,直接让他<0的时候n自增一次,然后指针跳过一个不就能实现了吗。。。
结语
字符串还好,c语言那会学过,基本都没啥问题,除了编码不同的时候,比较搞事情。