structPointer
前言
结构体也不算陌生,特殊的是给结构体赋值的时候。
复现
1 | typedef struct Box{ |
typedef是起到一个起别名的作用,例如我们声明typedef int in;,那么后面定义一个int变量的时候就可以in a = 0;。struct是声明结构体类型的关键字,在固有印象里结构体应该是这样的:
1 | struct HHH{ |
定义一个HHH结构体时,我们可以用HHH h;或者struct HHH h;
当我们在结构体后面放置额外的变量名时:
1 | struct HHH{ |
这个时候后面的三个变量名就是表面我们再创建结构体HHH的时候同时声明了三个HHH类型的变量,一个正常的HHH h1,一个长度为10的结构体数组,以及一个指向这种结构体的指针。
然后回到我们刚开始说的:
1 | typedef struct Box{ |
那么这个时候box还是一个提前定义的Box box变量吗?
答案肯定是否,因为typedef是起别名的作用,那么跟随在后的变量名,都将是结构体Box的小名。
*PBox理解就是typedef Box *PBox,说人话就是将Box的指针写法改名,声明变量的时候使用PBox xx,就可以不用再加*号。
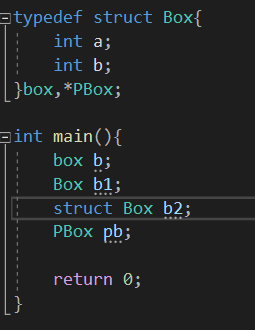
注意:别名起的跟结构体名称一致无意义,且指针类型时也不允许跟结构体重名
前言
大致回忆一下结构体的用法
正文
1 |
|
b.a是我们正常使用结构体访问成员的时候的用法,但是发现在指针的情况下,访问方式变成了->。
不过->这种方式在class的时候才会有更直观的体会,目前先不管,只需要知道指针类型结构体访问成员使用->即可。
结构体在反汇编下
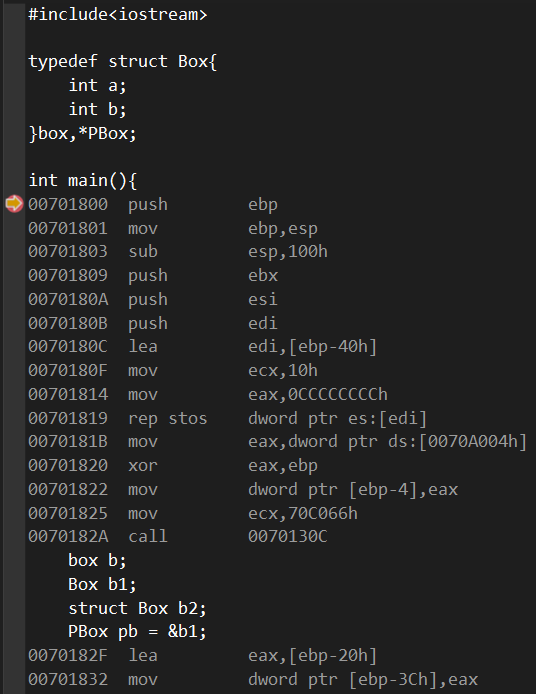
这里有点有意思的就是能看到我们在源代码里是清清楚楚明明白白真真切切的声明了结构体,但是反汇编下却没有对于结构体的代码,要知道汇编是源代码翻译过来的产物。
大致上的理解可以认为结构体就是自定义变量类型,类似于int,char之类的,计算机在编译的时候不会翻出它们的源代码,但是计算机已经能知道它们所需要的空间。我们声明的box里面有两个int变量,int类型在内存占用四字节,所以计算机就会把前面的四字节认作为box.a,后四字节认为是box.b。
指针结构体的地址问题
指针自然是需要申请地址或者指向一块地址,但是堆区的数据较为灵活,属于不确定率高的,而栈区则是有可能被查出的,或者说通过偏移量去计算。
1 | box b; |
反汇编可能不会很明显,但是浅看地址偏移量看个大概吧
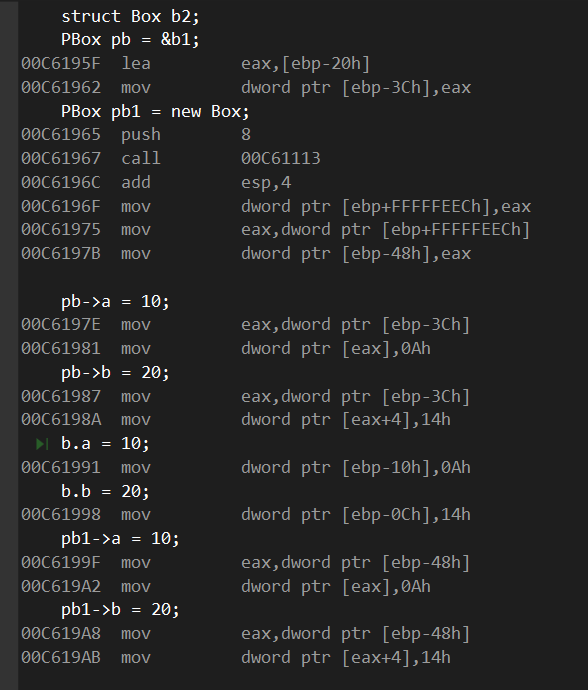
首先就是new的时候反汇编的操作和后续给pb1赋值的时候ebp的偏移量和pb赋值的偏移量明显的差距。
最直观的就是new一个Box的时候,push了8,这就是两个int类型占用的大小
说到结构体大小,额外提一点内存对齐
内存对齐
1 | struct HHH{ |
问,HHH结构体占用大小,凭借朴素的情感,4+4+2 = 10。答案是错的,因为内存的逻辑顺序就是连续,所以当出现两个int之后,又出现了一个short,编译器就会对short进行填充优化变成四个字节,至于填充的字节默认下不使用。
当然内存对齐的参照有很多,会根据不同操作系统类型,或者不同的对齐倍数设置和整体之间的参照,此处简单过一遍。
1 | struct HHH{ |
有兴趣也可以自己写然后计算一下,和sizeof做一个比较。
结语
结构体指针其实也没有太特殊,无非就是看重一点内存和访问方式吧。