function
前言
函数是指一段可以直接被另一段程序或代码引用的程序或代码。也叫做子程序、(OOP中)方法。
在程序设计中,常将一些常用的功能模块编写成函数,放在函数库中供公共选用。要善于利用函数,以减少重复编写程序段的工作量。
函数分为全局函数、全局静态函数;在类中还可以定义构造函数、析构函数、拷贝构造函数、成员函数、友元函数、运算符重载函数、内联函数等。
正文
简而言之就是封装好的功能,通过特定方法调用。
1 | /* |
类型可以各式各样,但是要有准确结果和一定的复用性,不然写着也没啥用处。
自定义函数声明前后问题
1 |
|
这种情况下,自定义函数写在main函数之前,则不需要额外的单独声明
1 |
|
假如实现的部分写在main函数之后,则需在main函数之前声明一个模板,或者在main函数内声明,区别就在于作用域不一样,在main函数之外声明的具有全局性,main函数之内声明的就是局部函数。
但其实不跨文件,终归都是在main函数里面运行,写在外面主要是好区分吧。
形参与实参
1 | int add(int a, int b){ |
注:这里的变量a和变量b实际上是不存在的,它只是一个类型参照,只有当你的形参被调用才会分配内存,调用完后立刻释放,所以形参只在函数内有效,并且你传递的变量跟a和b重名也没有关系
故此,我们称函数里的参数为形式参数,这里简称形参
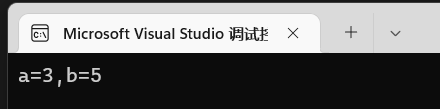
1 | int main(){ |
此处的i和j,是实质的变量,它俩声明的时候就占用了内存空间,进行函数传递的时候,他俩就是实际参数,简称实参
在此处也要引出另一个点,实参传递给形参的只是一个值,这个值在函数内怎么变化都不会影响实参。
经典swap问题
1 | void swap(int a, int b){ |
在形参和实参的时候解释过了,实参传递给形参的时候,只是传递了值。就是相当于激活了形参,形参拥有的只是实参的值,用完形参就释放了。所以这里a和b并不会交换值。
但如果想要真的交换两个变量的值,就需要对它的地址进行操作
C语言swap
1 | void swap(int *a, int *b){ |
C语言没有引用这个特性,所以依靠的是指针
而c++则都可以实现
数组参数
上述的swap问题所使用的形参是指针类型,此处提及数组参数的时候
参数为数组时:
1 | void sortInt(int ch[]){ |
这里需要强调一个问题,就是印象中,声明数组必须指定大小,除非是初始化的时候写好了。
那么作为形参的数组为什么不需要指定大小?
底层中,数组就是指针实现的,所以c语言和c++在编译的时候不对形参数组大小做检查,因为形参接受到的是实参的首地址!
不信的话可以sizeof查看这个数组的大小:
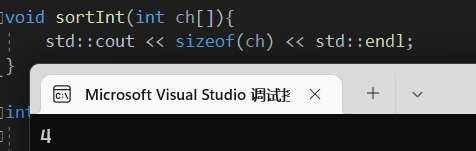
如果你以为这是变量类型的大小就错了!此处是在x86情况下的指针大小,我们再看x64下:
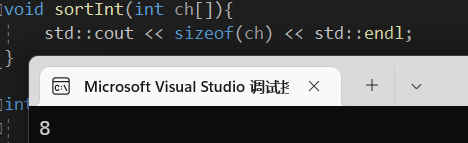
发现结果是8,这也就是表明了这个大小代表的是指针的大小。
提到soft,我们可以配合冒泡排序对数组进行排序
1 | void sortInt(int ch[], unsigned len){ |
结果为:
可以先不管算法,我们看到排序的时候函数形参除了数组还有个长度,当在我们印象里数组的长度似乎可以通过sizeof(ch)/sizeof(ch[0])得到,但是这里为什么不能这么写。
- 我们之前说过,形参数组接收到的是实参的地址,也就是指针,而指针在x86下占用4字节,x64下占用8字节,当处于x86环境下,
sizeof(ch)/sizeof(ch[0])就变成了4/4 = 1;故此循环就没能跑起来。不信邪的可以debug测试看这句表达式的值。
然后就是模板问题,数组底层是指针,但是在设置形参的时候,使用数组和指针给人的第一印象是不一样的
1 | void sortInt(int ch[], unsigned len){ |
再不看函数名的情况下,只看形参,不一定就能看出第二个函数是干什么的。
当然效果都是一样的,只是在可阅读性上,我们尽量不为难自己人
然后是多维数组,例如二维:
1 | void sortInt(int ch[][], unsigned len){ |
这种写法肯定就不合适了!
学过数组的都知道,二维数组可以不声明有多少行,但是要声明多少列,从实参传递来的是数组的起始地址,在内存中按数组排列规则存放(按⾏存放),⽽并不区分⾏和列,如果在形参中不说明列数,则系统⽆法决定应为多少⾏多少列,不能只指定⼀维⽽不指定第⼆维
形参是实参的模板,所以形参肯定也要是合法的。
引用参数
引用就是int &a = b;,放到函数里
1 | void hhh(int &n){ |
引用变量可以修改被引用的变量:
1 | int a = 10; |
得到结果: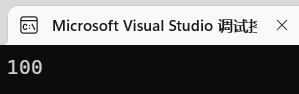
如果不想被修改,那就只有在类型前加上const限定为常量。
之前提到过引用其实就是弱化的指针,放到形参上他俩的区别就是指针可以传入nullptr,也就是空指针;而引用不能传入nullptr。因为引用是必然要初始化的,指针稍不留神就会漏掉。
引用作为参数的时候,对于结构体才会用的比较多,现在的体会比较少
不过对于swap函数,引用就派上用场了
1 | void swap(int &a,int &b){ |
效果也是一样的,对比指针还要用*号取值时更直观点。
默认实参
1 | void hh(int a,int b,int c,bool d){} |
我们在声明函数的时候,形参是各式各样的,但是针对一些值,比如布尔类型,他就两种结果,有的时候我们就想不声明了,让他默认有一个值,方法也很简单:
1 | void hh(int a,int b,int c,bool d=true){} |
不想额外声明的可以提前定义一个值作为默认参数
注:默认参数可以有多个但只能放在最后面,否则调用函数时hh(1,3, ,3)在中间留空,则导致参数不匹配了。但如果形参都设置了默认值那也无可厚非,参数自然能匹配上
不定量参数
学网络的时候常在cmd中用ping命令,ping是人为写好的功能,一般存放在C:/Windows/下,ping 可以是ping网址也可以pingIP地址,但是这俩参数都是不确定的,并且还有一些其他功能-t 持续ping之类的,这些都是不确定的。
在老的编译器那会,创建模板的时候main函数括号里是有两个形参的,这好像也是c语言规定的主函数的形参就俩
1 | int main(int argc,char *argv[]){ |
不好理解的可以直接写段代码看看:
1 | int main(int argc,char *argv[]){ |
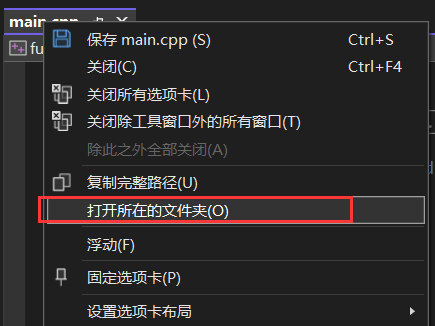
右击main函数打开所在文件夹,然后找到Debug目录下,不用看x64,如果你是x64编译的就去找x64下的debug。
进去之后看到这个项目名.exe程序,右击文件夹空白地方打开终端:
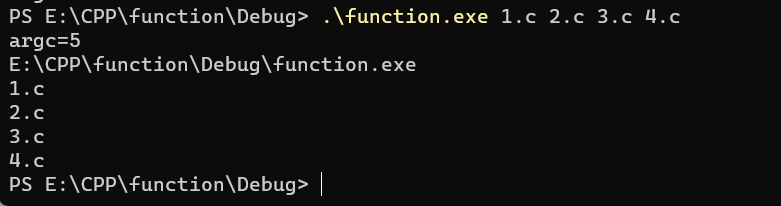
.\执行程序 参数1 参数2 ......参照这样执行,我记得这好像叫重定向。
ps:之前linux玩多了,linux下执行的时候都是./xxx,而windows则相反.\可还行
然后印象里当初弄的时候好像第一个接受的参数应该是这个程序编译后的名称,但这里是显示一段较为完整的路径了,暂时没研究为什么,可能是不是在全局命令下执行的吧,就自然而然的带上了路径+执行程序名称
argv就像一个数组制作的字符串,输入的参数会分配到一片连续的空间,并且以0结尾。
结语
函数的模板其实没啥好写的,用着用着就习惯了