function2
前言
之前提到过函数是什么类型的就需要返回什么类型的值,正常变量类型都还好,当指针和引用的时候就有意思了
正文
1 | int main(){ |
C语言的字符串最常用的就是数组的方式声明,反正数组的底层就是指针,所以你用指针也行。
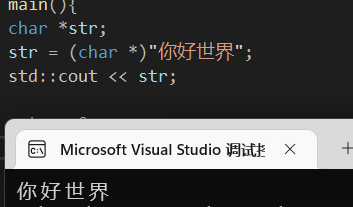
但是在使用指针强转的时候,右值的这串中文它属于一个常量,也就是说指针指向了一块常量内存,你就没办法修改它了。
如图: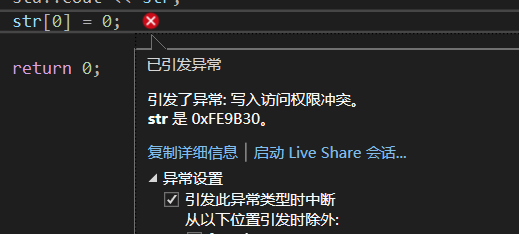
编译器给出了错误,就是说我们没有权限对这块内存写入。
要套娃的话就是赋给字符串然后强转再改,或者拷贝给另一个字符串,反正能得到结果是首要目标。
这里就利用自定义函数去拷贝修改返回一个想要的值。
1 | char* cstr(const char *str){ |
拷贝函数memcpy(),不过要知道str的长度和一个跟str一样大的指针变量
可以直接在cstr里面for循环求长度,也可以自定义函数,因为学的函数这块就姑且用函数了。
1 | int cLen(const char *str){ |
结果如图: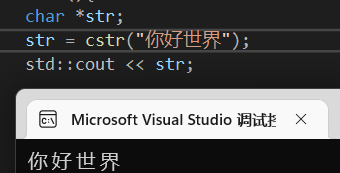
这个时候你再修改main函数里的str就无所谓了,不是常量了,虽然在空间角度上是有一定浪费.
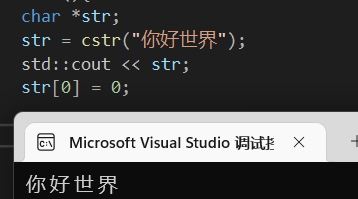
就不打印了毕竟中文占两字节,改了一个估计开头要乱码。
假设一个游戏有这个一个结构体,做初始化角色用。
1 | struct Box{ |
我们给通过函数传值的时候,怎么传会更友好。
1 | Box createRole(const char* name, int hp, int mp){ |
如果在函数里额外声明一个结构体变量赋值返回,显得很2
因为对于内存上它反复开辟销毁很麻烦,虽然字面上很好理解是干什么的。
但如果是指针类型的结构体则友好很多,这里就要改一下结构体了
1 | typedef struct box{ |
对于返回指针类型的函数时,我们需要额外注意这个指针变量不要返回局部变量
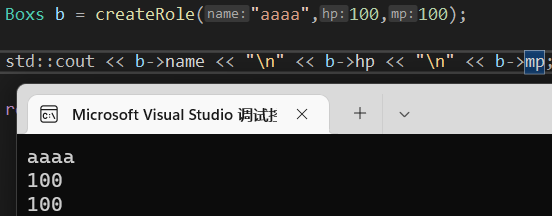
还有一种引用的方法
1 | typedef struct box{ |
引用和指针,指针传递失败还有空指针,引用没有空指针
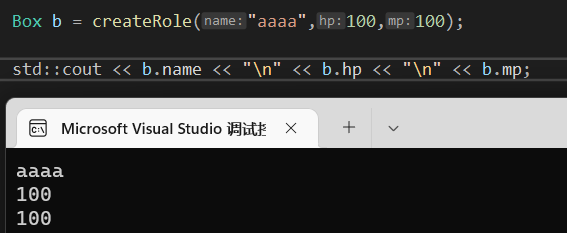
如图可以看到,当函数是结构体指针类型的时候,接受的一方也得是结构体指针
而在引用的时候,接受的一方只需要是相同的结构体即可。
再看引用做参数时的问题
1 | void Add(int x){ |
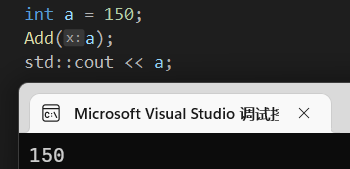
这个代码一看就知道没有意义,因为传进去的只是一个值,x加完离开函数就销毁了。想要真的改变就可以用引用
1 | void Add(int &x){ |
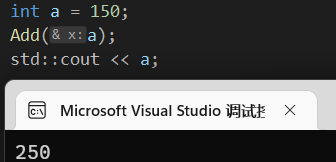
引用作为参数的时候,它更加严谨,当传入的变量类型不一致的时候,引用是不能完成操作的
1 | void Add(int &x){ |
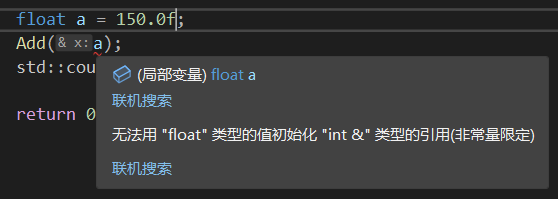
很直观的就报错了,甚至都懒得进行隐式转换截断掉后面小数。
1 | void Add(int x){ |
当形参不是引用类型的时候,编译器也懒得鸟你,大不了隐式转换掉。
数组的引用变量
1 | int ch[10]; |
这个写法直接无情报错: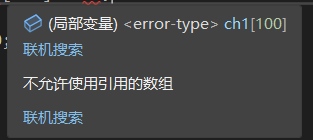
它说不能使用引用的数组,这其实是编译器没有理解。
1 | int ch[10]; |
先告诉编译器ch1是一个引用,然后是一个引用长度为10的数组引用。
引用也保持了数组要明确大小的问题,引用数组长度10,被引用的对象的长度也只能为10,否则编译不通过。
使用引用数组作为形参的时候
1 | void sumI(int(&ch)[10]){ |
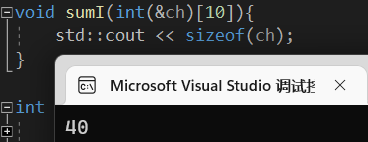
它可以用sizeof计算长度,这个相对于指针和不定量参数的时候会方便很多。
而且可以使用新版for循环
1 | int sumI(int(&ch)[10]){ |
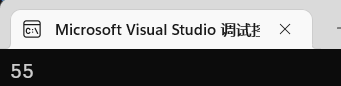
还是挺得劲的。
仅限于数组长度明确的时候得劲
strcpy_s
1 | _Check_return_wat_ |
这是在string头文件中的定义。
为什么会有_s的版本,是因为strcpy原则上是不安全的,它存在致命的缺陷就是缓冲区溢出
缓冲区的溢出就是程序在动态分配的缓冲区中写入了太多的数据,使这个分配区发生了溢出。一旦一个缓冲区利用程序能将运行的指令放在有 root权限的内存中,运行这些指令,就可以利用 root 权限来控制计算机了。
默认情况下strcpy都会认为你的缓冲区够大,就只管填充。
回过头来看strcpy_s的形参,char*和char const*都好理解,不能改变的说明是要被拷贝的字符串
至于rsize_t速览定义看到其实是一个无符号整型
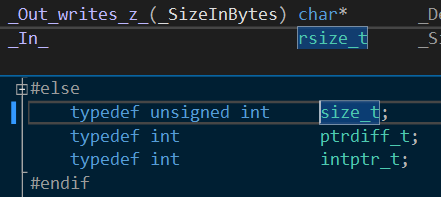
猜测可能是长度有关的。
大致使用起来就是strcpy_s(str,strlen(str1),str1);
简单的百度了一下,strlen要+1。strcpy_s(str, strlen(str1)+1, str1);
+1大概是因为stelen没有统计到\0吧,不过如果缓冲区大小不够,发出异常这个不晓得怎么操作
按照我们现学现卖就是if判断大小,不行就提示,抛出异常这个面向对象的特点要放后面了。
ps:像当初刚打开vs2019的时候,scanf就会报错,说不安全,要用scanf_s是一个道理,这些都是后面加的安全函数。
结语
欲知后事如何请看下回分解