function4-本质和函数指针
前言
vs ide 可以选择x86编译和x64编译,同时一个项目它也存在两个版本
- debug 版本就是常说的测试版本, bug就是漏洞的意思。
- release 版本就是正常发行版本, 说明这个版本的漏洞相对于debug比较少,毕竟是先测试后发布。
正文
本质
debug的反汇编会多一些内容,这里使用release版本好分析。
在项目-属性-c/c++-优化中关闭优化:
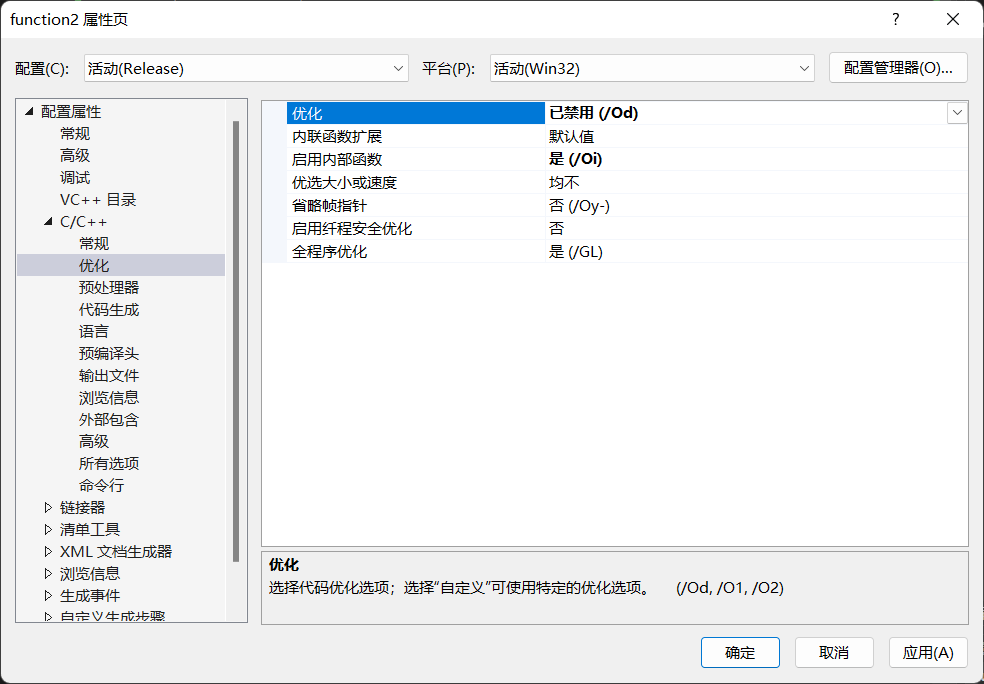
原则上优化肯定会带来性能上的提升,但不利于人为分析。
1 |
|
老样子在int c那里打断点运行然后反汇编:
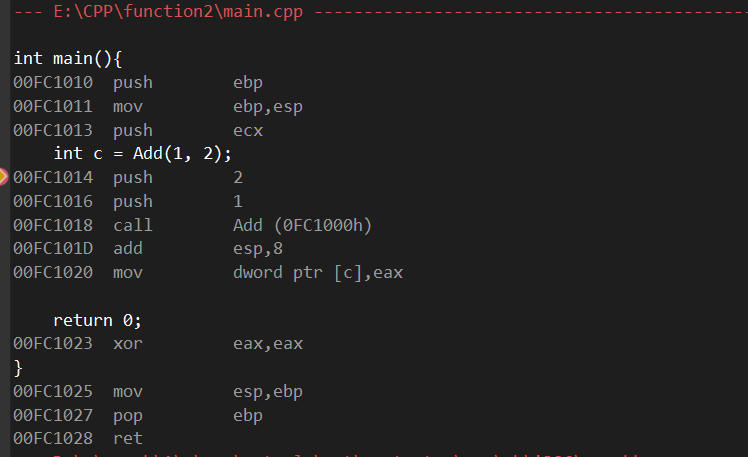
可以看到整体反汇编代码还是很简洁的。
同时int c = Add(1,2);的下面有一句call Add(0FC1000h)其实就是要跳转到add函数的位置
ps:我打开了显示符号名,所以call才会显示函数名,关闭显示符号名则只有后面的地址,怎么好理解怎么来
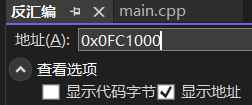
在上面的地址栏里输入0x add的地址,不用加那个h
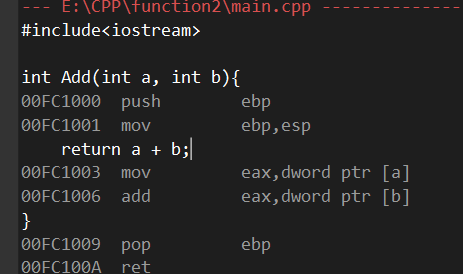
可以看到的确跳转到了add函数的反汇编区域,并且add函数的第一个指令地址起始值也是00FC1000
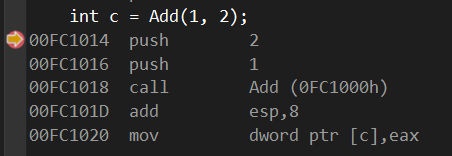
回到int c = Add(1,2);的反汇编,在跳转到Add函数前,编译器push了两个值分别是2和1,这正好是我们传递给Add的参数,只不过是后面的先push进去。
- ebp 可以叫做栈底寄存器
- esp 可以叫做栈顶寄存器
- 栈的内存地址生长方式是由高到低
00FC1003 mov eax,dword ptr [ebp+8],就是将ebp+8这个地址里的值赋给eax寄存器,ebp在跳转到函数的时候就被赋予了esp的值,大概就是传递了一个临时变量的值。00FC1006 add eax,dword ptr [ebp+0Ch],这里又让eax add 加上 ebp+0C这块地址里的值,0C和8的差是4,说明可能是int类型的数据。
然后pop ebp,把ebp弹出栈了。——目前还不太好解释
最后ret ,跟return似乎有关联,就是告诉编译器这段运行完了,可以回去了。
按照我个人的理解花了草图:
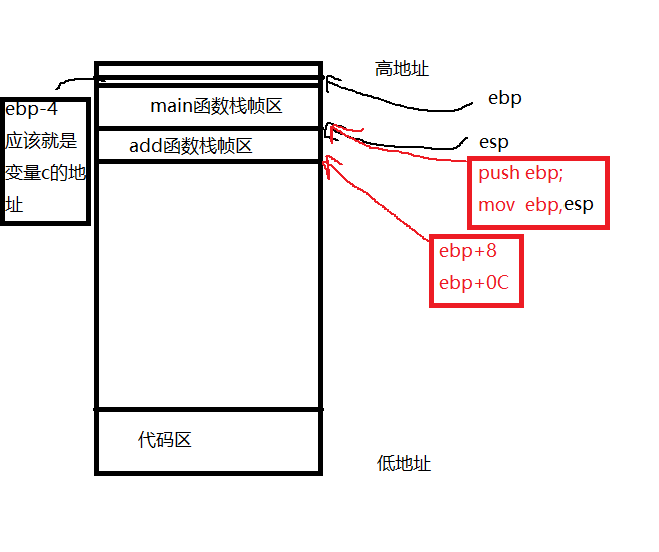
红色是跳转到add函数的时候发生的,黑色则是main函数里面正常的情况。
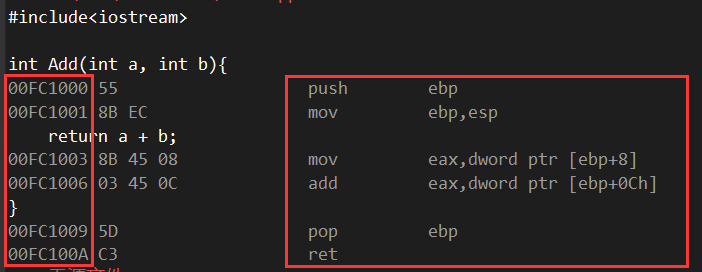
编程语言-汇编-机器码
我们通过反汇编得到的不管是左边的内存地址还是右边的指令都还是人为能够看明白的操作,而中间的8B EC那些才是存在本地硬盘上让机器读取的。
ps : 还有一层二进制数据没转化
再反汇编的时候,我们看到call 函数地址,说明了函数也有内存地址。
直接打印就可以得到地址。
1 | char *p = (char *)Add; |
既然是地址,就能通过地址显示内容,但是函数里的内容会是什么?
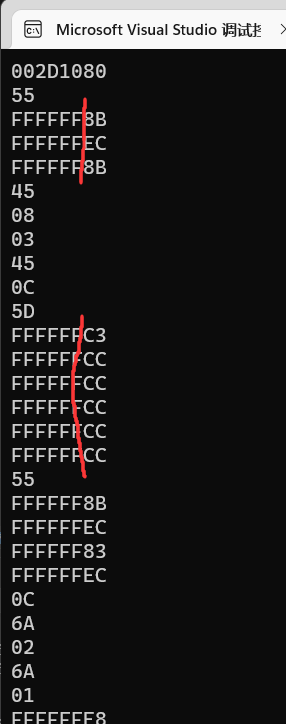
这样看还是有点不直观,可能因为p[i]被当成指针地址四个字节四个四个字节读取了
1 | char *p = (char *)Add; |
把他强转成无符号的char类型数据,再次打印:
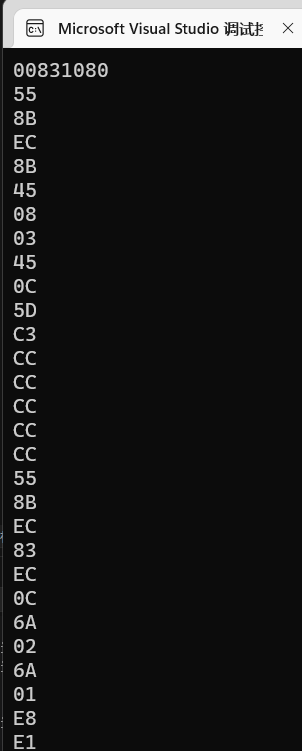
发现似乎有点眼熟?
对比我们之前截的图,在显示了代码字节的情况下【中间部分】:
跟函数内存储的字节是一模一样的顺序下去。
想看二进制的可以引用头文件bitset来着,然后std::bitset<8>控制二进制流输出
不过反正也看不懂。16进制都很勉强了。
函数指针
在C语言和c++里,只要是有内存地址,就会被指针拿来玩。
对于指针函数,很好理解就是返回一个指针的函数
1 | int* hhh(){ |
对于函数而言,比较重要的是参数和返回值,在反汇编中,函数的地址
那么如何定义一个函数指针?函数返回类型 (*函数指针变量名)(参数类型 参数名称,......)
例如int (*pAdd)(int a, int b);
当然void类型依旧可以使用。
其次就是参数的问题,形参不仅是接受传递进来的值,形参名在函数内实现会被用到,但是定义的时候是可以忽略形参名的,比如int (*pAdd)(int , int );,毕竟他可以指向一个函数,关键点还是在于那个函数怎么实现。
1 | int (*pAdd)(int a, int b) = Add; |
打印后结果: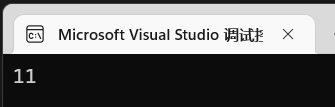
函数指针也是指针,所以它的大小也不用多说,x86下自然为4字节,x64下为8字节。
有疑问可以自己sizeof查看。不过这是基础概念了。
当遇上类型不同的函数时,万能的强转大法又回来了
1 | float Add(int a, int b){ |
格式如代码所示,依旧是采用返回类型 * 参数类型,参数类型
注:即使函数原型返回类型是float,但是强转之后为int,当输出的时候也会隐转成int类型,float转int的特定就是没有四舍五入的说法,直接抹去小数点后面的
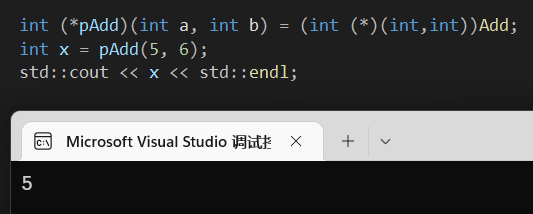 可以看到(5+6)/2应该是5.5,但是强转的时候改变了类型,所以结果变成了5。
可以看到(5+6)/2应该是5.5,但是强转的时候改变了类型,所以结果变成了5。
强转成char的话,如果在ASCII码内,就可以打印正常的字符,不然出现乱码也说不定。
但是相比较,函数指针的写法有点长,虽然cv码农问题不大,但是之前C语言学过typedef,这里就能用上
1 | typedef int(*piAdd)(int, int); |
这样看上去整体简洁一些,带有C语言的味道,而c++则是可以通过using实现
1 | using pI_Add = int(*)(int, int); |
效果也是一样一样的。
总结就是三种声明办法:
1 | typedef int(*piAdd)(int, int); //声明函数指针类型 |
然后就是结构体参数的时候
1 | struct Box{ |
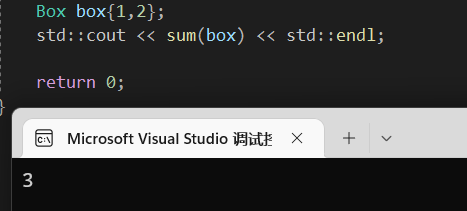
结果自然是3,但是写成函数指针的时候,参数如何操作。
1 | struct Box{ |
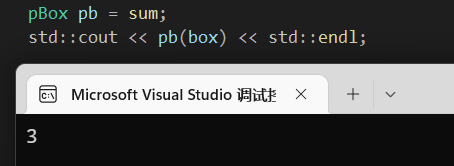
当然结构体原型就是两个int类型的参数,所以直接使用两个形参效果也ok的。
1 | using pBox = int(*)(int,int); |
结果如图: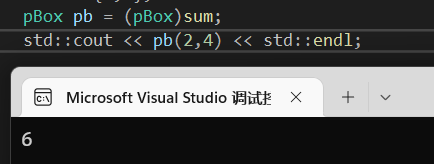
当然不用2,4用box的参数也无可厚非,意义是相同的: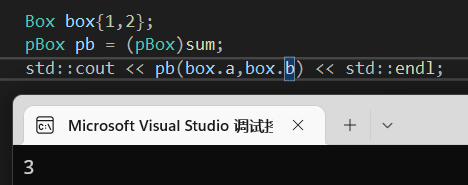
转到反汇编查看当传递结构体进去时发生的变化:
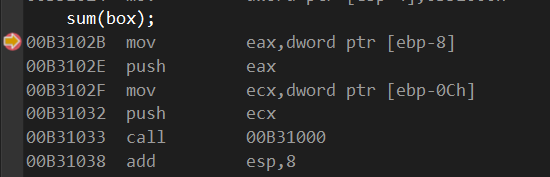
call 不用多说,就是跳转到sum这个函数去,那么在跳转之前先传递了两个值
一个ebp-8 一个ebp-0C其实也就是ebp-12,两者差4,说明极有可能就是结构体内的参数
打开显示符号名,发现: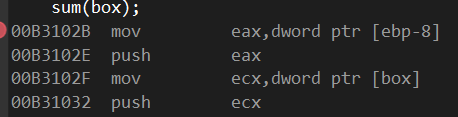
ebp-0C变成box结构体变量名了
参照之前百度,栈的内存地址是由高到低,由右向左
故此推测ebp-12是box.a的值,而ebp-8那块地址上就是box.b的值
再到地址栏那块输入0x00b31000,跳转至sum函数处:
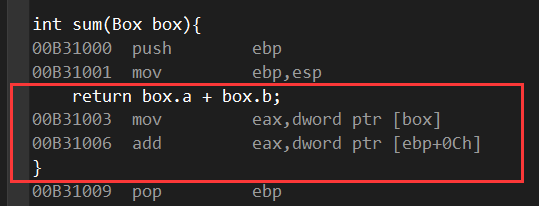
也就是说先将a的值传给eax寄存器,再将b的值给eax相加最后返回。
自己推敲一下反汇编
注:项目属性关于c/c++的优化处于禁用状态,然后模式为release
之所以这么改是因为debug的内容比较多,再加上优化的话更不适合新手推敲了。
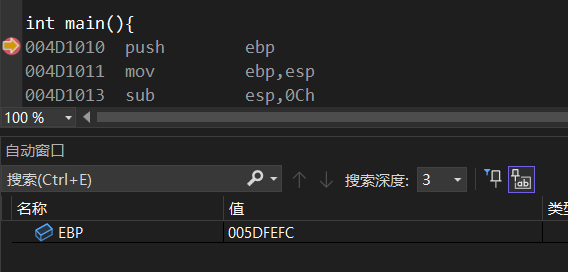
在主函数压入栈时,push ebp,ebp那会的值是005DFEFC
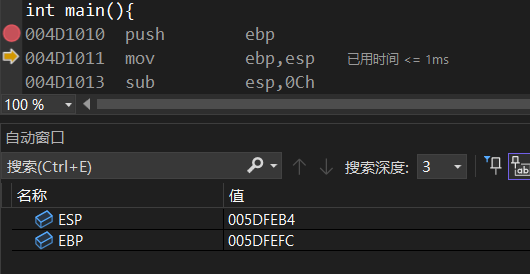
单步调试,esp的值还没同步ebp,等mov这条指令走完之后看到
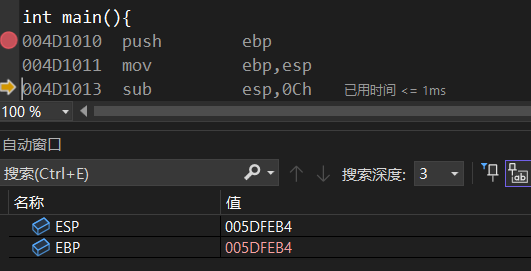
现在看到esp和ebp持平了。sub是减法的意思,再往下走
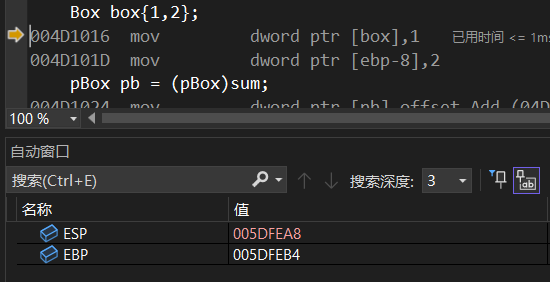
esp-0c得到的结果就是005DFEA8,ebp不变
用画图表示大概就是这样: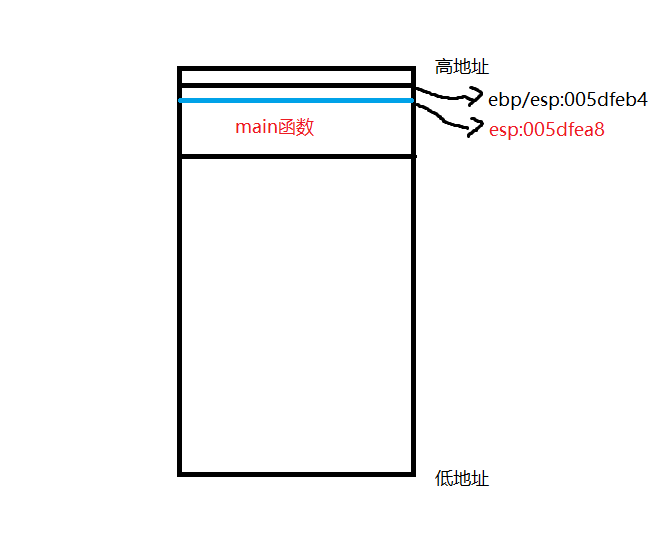
然后在看后面的汇编: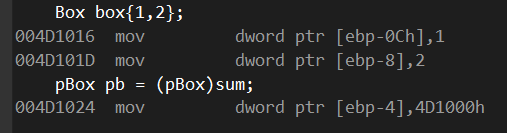
自己画图表示的话大概是: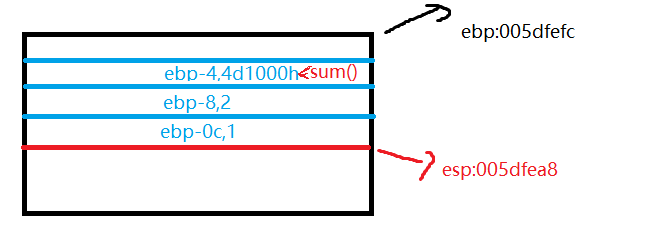
然后我就发现不对劲的地方。。sum和add好像还是被优化了,因为两个效果好像类似,所以函数地址居然都是指向了add
也就是: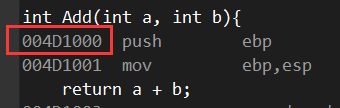
既然已经被优化了那就先不管了。
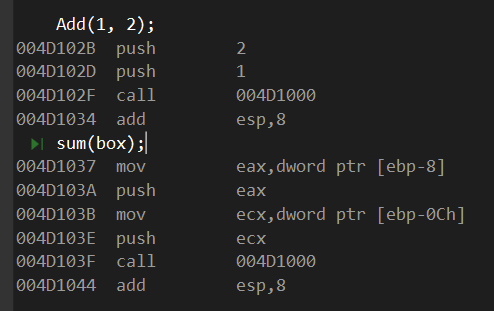
add函数里的两个算是常量了,都被直接push进去,然后call到add函数位置。
至于sum(box),因为在上面初始化box的时候就看到了1和2存在哪个地址了,所以这里看起来并不费劲。
ebp-8存的2,ebp-0c存的1,都分别把值传给一个寄存器,然后push进函数。
最后输出的那句: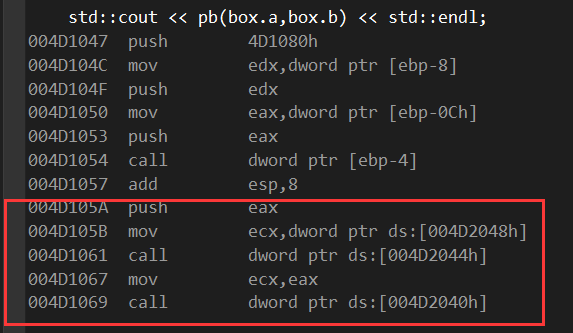
前面也不难看懂,第一个push不知道是不是std流,先不管,然后传递box.b的值给edx,在push edx;传递box.a的值给eax,在push进去;call ebp-4的地址上就是我们声明的pb函数指针。最后面那几句还真不之地干啥的目前。
自定义函数指针做形参
1 | using pI_Add = int(*)(int, int); |
结果自然显而易见:
虽然以现在案例的复杂度肯定用不上,等以后了没准还真有这种写法。
函数指针和指针函数?
指针函数就是指一个返回值是指针的函数
而函数指针虽然本身也是一个指针,但是它是指向一个特定类型的函数,它的返回值看的是指向的函数。
硬要区分的话函数指针的变量名带阔号了哈哈哈!
结语
六一的快乐停留在了幼稚园~