translater-定义/声明/文件
前言
- 声明
- 定义
#pragma once是一个比较常用的C/C++预处理指令,只要在头文件的最开始加入这条预处理指令,就能够保证头文件只被编译一次。
#pragma once是编译器相关的,有的编译器支持,有的编译器不支持,具体情况请查看编译器API文档,不过大部分编译器都有这个预处理指令了。
#ifndef,#define,#endif是C/C++语言中的宏定义,通过宏定义避免文件多次编译。所以在所有支持C++语言的编译器上都是有效的,如果写的程序要跨平台,最好使用这种方式。
#ifdef 和 #define 显然 if 有define这个宏,才会执行里面的内容
正文
一般情况下:声明就是告诉编译器存在这么一个东西,就有点像函数;而定义则是申请了内存,就像用到了变量。
但是并不是绝对的,概念性的东西还是看人为理解。
函数
1 |
|
在学c的时候就知道编译的时候是逐条执行,程序运行先从主函数开始,所以当自定义函数写于主函数之后时你去调用,编译器找不到这个函数的声明,他不知道这个函数在哪,函数有几个形参,函数里面要进行什么操作,函数要返回什么值。
解决方法就是要么将自定义函数全写在主函数之上,或者在主函数前或里面声明。
1 | int add(int a,int b); |
也就是说int add(int a,int b); 这一句就是函数的声明,那么定义自然就是{}里面的内容
ps:声明的时候可以不写函数形参的变量名~ 反正这个变量名只有在实现的时候才用到。
所以int add(int a,int b); 在声明的时候可以写成int add(int,int);
甚至说声明的时候变量名和定义的时候不一样也没啥太大关系
除了主函数调用其他函数的时候要声明,函数之间的互相调用如果不是正常顺序也要提前声明
1 | void abc(){ |
这样肯定会报错,因为abc在cba之前声明和定义了,解决方法也跟主函数那会说的一样。
变量-extern
我们常说定义一个变量而非声明一个变量
是因为定义变量的时候一般都进行初始化或者赋值操作了,他不是一个模板一样的存在,而是已经实际开辟了空间。
1 | int a = 100; |
写在哪里不重要,对于变量而言默认就是定义。拿初值这个东西来判断变量是声明还是定义是不靠谱的,因为变量即使不初始化也会有值,只不过是随机产生的垃圾值罢了
当然作为变量想要去做声明,需要用到extern关键词。
1 | extern int a; |
但其实extern的本意是在全局的情况下做声明,目的自然是为了让其他函数或者其他文件能发现这个变量。
所以extern没必要放在函数里去用,而函数声明的时候其实自带了extern,不需要手动设定了,也就说函数自带全局特性。
内存分配
已知的有栈区和堆区
那么全局变量也有对应占用的地方
源代码也会有占用的地方
网上的图可能比较高级和详细:
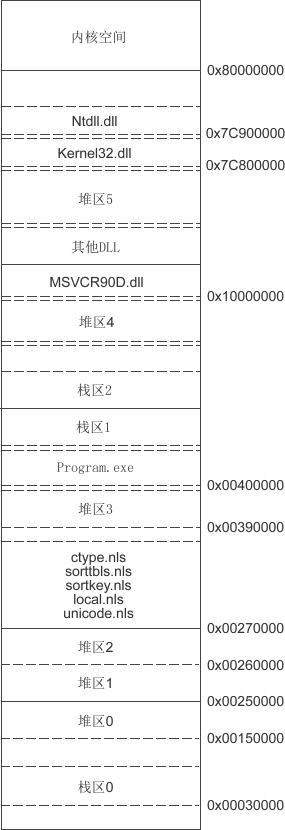
之所以会划分,是因为总不能运行一个程序就把所有内存都给他,那这样一下子就爆内存了。。
显然是挨个映射到各个区,不用就销毁来得自然。
x86的内存那会最高是4g,实际上倒是达不到,然后内核吃了一大部分,剩下的是给用户的。
内存简图没找到合适的,看什么时候有个合适的好理解。
头文件和源文件
在C语言中:.h的是头文件,.c就是源文件
而c++其实引用的标准头文件已经不怎么看到.h了,事实上也没差;源文件也就是.cpp的文件。
1 | //hello.c |
1 | //hello.cpp |
两种语言引用的标准头文件不同,输入输出自然也不相同,但是c++是C语言的超集,他可以套用c语言的内容,但是反过来C语言不能套用c++;
简单玩一下分文件写法:
1 | //function.cpp |
1 | //main.cpp |
创建两个源文件叫啥无所谓,但是记住一个程序只有一个main函数,所以分文件写也要注意不要出现多个main。
其次就是因为是项目文件,编译的时候一起编译了,但是如何在main.cpp使用function的函数呢?
前面提到过函数本身具有全局性,但是要先有一个声明.
1 |
|
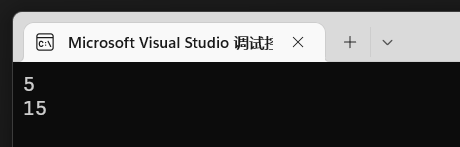
可以看到声明之后确实能用了,但是如果有很多很多函数,在不同文件想使用它们,每次都要声明一堆也很麻烦,这就要归功于inclue了,将这个文件当头文件引用之后就省去了许多麻烦。
创建一个function.h的文件,将函数声明放置其中。
1 | //function.h |
在main.cpp文件中引用头文件#include"function.h";
“”和<>的区别其实就在于前者是引用非库文件,后者引用的都是库里标准的头文件
插一嘴C语言编译过程的四个步骤:
C语⾔编译过程分成四个步骤:
- 由.c⽂件到.i⽂件,这个过程叫预处理
- 由.i⽂件到.s⽂件,这个过程叫编译
- 由.s⽂件到.o⽂件,这个过程叫汇编
- 由.o⽂件到可执⾏⽂件,这个过程叫链接
那么预处理的时候,它会将所有include的头文件或者宏定义替换展开成真正的内容,就比如头文件里面的声明和定义等。
编译事实上就是将高级语言逐步翻译成机器语言的过程,这里先翻译成汇编代码。【高级语言->汇编->机器码(2进制)。】
汇编也就是将汇编代码翻译成之前说的机器码。
链接过程使用链接器将该目标文件与其他目标文件、库文件、启动文件等链接起来生成可执行文件。
也说明了头文件不会主动编译,因为只有它被调用编译之后才会展开。这也就回到上面为什么不推荐头文件直接写定义,当另一个cpp文件也去包含这个头文件,编译的时候展开,会有多个函数发生重复定义现象。
如果能保证不被多次调用倒是能直接定义。
那么哪些适合写在头文件:
static
1 | static void hhh(){ |
由于static的限制,它只能在文件所在的编译单位内使用,不能在其它编译单位内使用。
也就是说写于头文件的静态函数,被其他文件引用后,不会互相访问,包括静态变量。
inline
1 | inline void hhh(){ |
内联就更不用说了,本身结构简单的话就直接被替换了,算是一种老式优化,所以也不存在冲突的问题,但是通过替换简单的代码,无非就是以空间换时间的做法。
结语
有的时候编译器能稍微人性化