【软件】vs2022控制台乱码
windows的根据地区选择编码一言难尽。。
前言
本文只是介绍几种情况的处理方式,仅供参考。
正文
1.乱码介绍
什么是乱码?粗略解释就是:
指保存内存的编码和输出内存的编码不一致,导致出现奇奇怪怪的字符。
更多详细介绍自行上网冲浪。
这点情况在windows中很常见,原因就是Windows的特色,它会根据地区默认选择你cmd/powerhell的编码。
打开cmd/powershll输入
chcp按下回车
如果你地区选择的是中国,那么回显信息为活动代码页:936。
而文本格式千奇百怪,也是拿捏不住的。
Linux默认都是utf-8的环境,相对比较省心不用你去改什么东西控制输出。
所以默认的vscode/vs201x的产品,或者是其他需要调用cmd/powershell的软件,都会存在这个问题。
vs的项目默认选择Unicode,你也可以改为多字节。
- 统一码(Unicode),也叫万国码、单一码,由统一码联盟开发,是计算机科学领域里的一项业界标准,包括字符集、编码方案等。
- Unicode中,我记得字符都占用两个字节。
- 随后的utf-x系列会有一定程度不同,而现在最大众的是utf-8,在utf-8中汉字占用3个字节,英文字符1个字节。
- ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。
- ansi也就是多字节
- 英文字符占用1个字节,汉字占用2个字节
注意:即便是占用大小相同,不代表存储的字符都是一模一样的顺序开始表达。
2.解决方案
2.1 糙糙的方法
- 将文本另存为gb2312/代码页936使其与之匹配,notepad++之类的软件操作比较快。
- 右击控制台-属性-改为旧版控制台,这个说实在没啥用啊,现在的系统不断地更新,改为旧版也同样不是很好的办法,而且不一定奏效——pass掉
- 控制面板-区域-管理-更改系统区域设置-选择beta版本语言支持
- 这个的问题就是,很多的老软件,他那会可能不是用utf-8创建的,会导致他们目录乱码之类的,所以也不是很好的办法。
2.2 关于修改注册表
反正只是改固定的cmd或者powershell而已不用怕啥,大不了改回来。
首先vs先下载个拓展商店,不用vs自带的下载是因为很慢很慢很慢。
搜索Force UTF-8(No BOM) ,记得看下概述Overview有写适用于vs哪个版本,别乱来。
BOM是签名的意思,有签名的utf-8文件的文件头存在表示信息,一眼就知道是这个格式,更容易解析吧。但是不是必需品。
双击即可安装,安装前请先关闭vs
这个拓展的作用是强制以utf-8 no bom形式保存所有文本文件。
如果有ANSI的需求大于utf-8,可以关闭这个拓展。
vs菜单栏-拓展-管理拓展-找到即可关闭或者卸载
然后修改下注册表。win + r打开运行,输入regedit,选择是>
路径为:计算机\HKEY_CURRENT_USER\Console\
我这会发现一个问题:
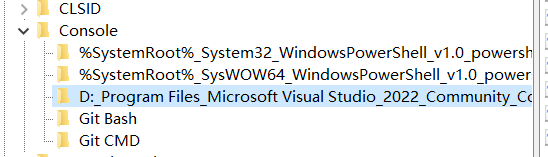
vs2022的控制台可以独立控制了
vs2019那会还没有这个选项的,那会我是直接改了上面两个
直接选择这个CodePage字段,右击选择修改,然后十进制,改为65001即可。
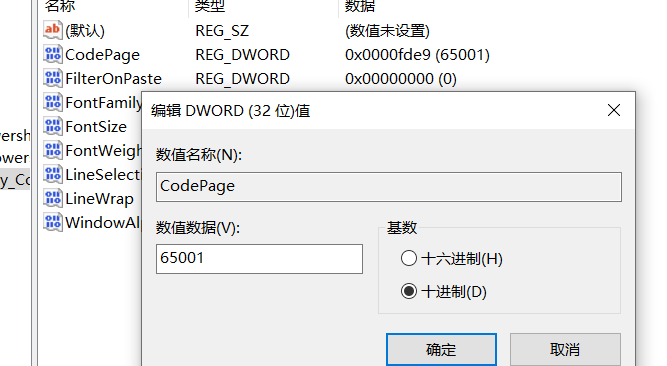
这样你通过FILE指针读取的utf-8文件就不会有乱码了。
如果注册表里面没有vs2022这项就只能在上面两个里面新建DWORD数据了。
名称要保证是CodePage然后十进制值是65001,十六进制用win自带的计算器算一下都行。

ps:不过我好像忘记了,改了这个是不是只对powershell有效来着,因为vs的控制台虽然是独立的,但是还是基于cmd,vscode那些倒是可以直接选择powershell。
或者要自行百度一下添加cmd项的操作了。我记得之前是找到过执行脚本的,copy下来改成bat直接管理员运行。总不能自己根据这个powershell一个个建过来吧有点累的。
当然,上述操作只是说,让控制台能输出utf-8的文字,但是文本如果是936的输出就又有问题了?
所以如果你尝试将所有控制台都改成65001的话,就要确保其他的文件都得是utf-8,不能匹配就肯定就乱码
2.3 关于软件
先前也说过,utf-8是Unicode的拓展,utf-8表示中文需要三个字节,而unicode是万物都两个字节,ANSI是中文两字节英文一字节。
vs中,char占用一个字节,string就是一堆的char。
vs中还有一种宽字节,wchar_t,占用两个字节,至少在vs这是的。 —— 那么用wchar去存储unicode类型的数据就很容易。
并且,vs有大量的宏,会区分多字节和Unicode的情况。
vs有一个函数WideCharToMultiByte是可以处理char和wchar。可能要引用windows.h
举个例子比如说字符串。有的框架或者特殊类返回的结果可能会根据你项目属性的编码而改变。即项目unicode,返回宽字节数据。
wchar的类型,我们输出肯定要用std::wcout输出。
但是一会cout一会wcout很麻烦,而且将来要是存储然后解析也是一个问题。
那么就会考虑说,是不是能够把这个wchar数据转成char数据。
1 | std::string toString(const std::wstring wstr) { |
这个函数的返回值是字符串的长度,第一次不转换但是变相的读取出宽字节字符串的长度,给后面resize做准备。
第二次转换之后,就可以正常return了。
这个概念其实会很抽象,等到将来用的多了就通透了。
小结
救赎之道就在其中。
会用就好,因为生活充满变数。