pointer
c/c++的万恶之源
- 指针
概念
指针,是C语言中的一个重要概念及其特点,也是掌握C语言比较困难的部分。指针也就是内存地址,指针变量是用来存放内存地址的变量,在同一CPU构架下,不同类型的指针变量所占用的存储单元长度是相同的,而存放数据的变量因数据的类型不同,所占用的存储空间长度也不同。有了指针以后,不仅可以对数据本身,也可以对存储数据的变量地址进行操作。
——摘自百度
因为运行一个程序,需要消耗内存,程序当中的变量各自有占用的地方,通常以十六进制表示,用visual studio反汇编的时候就能看到前面有一串长的字符。
正文
不同类型的变量所占用的内存也各不相同,有基础的应该都知道,目前先不说32位操作系统的情况,以64位操作系统为例。
tips:int 类型占用 4字节 = 32比特,一个比特可以表示0或者1
指针的要素就是要操作对象的内存地址和大小
基础语法
1 | //数据类型* 变量名称;例如: |
初试指针
打开编译器,运行:
1 | int main(){ |
vs2019开始变量不初始化会报错,所以我们这里采用int *p{};
可以看到: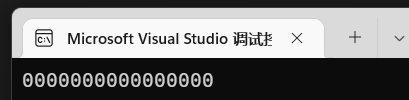
可以看到打印的是多个0,那么接下来可以看看一个其他变量的地址。
1 | int main(){ |
可以看到结果是一个十六进制的数: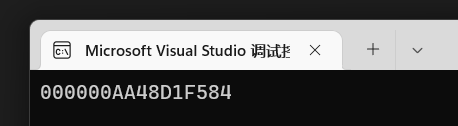
为什么要用&呢,在学习C语言scanf语句的时候,我们知道了往一个变量写入值的时候需要知道变量的地址。此处概念相同。
其次,指针的类型必须和获取地址的变量类型一致。
有意思的是,这个地址,每次生成程序都会发生改变,
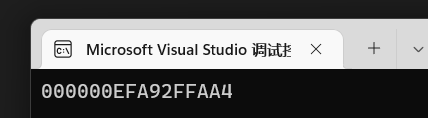
其原因就是因为这个变量是个局部变量,将其提升为全局变量则内存地址固定。
那么明白了不带*的时候输出就是地址,就可以猜到带*输出时表示为a的值:
1 | std::cout << *p << std::endl; |
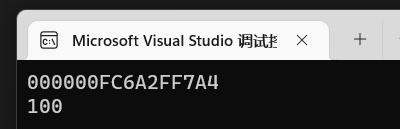
有聪明的小伙伴就会想到,*p代表值,那么\*p=200是不是就可以修改a的值呢?
1 | int a = 100; |
ok,结果当然是: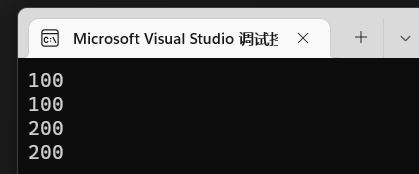
tips: 这里也可以不用*p = 200, 将a = 200;效果也一样
同理,不带*的时候,可以给指针换个地址。但注意不要是非地址以外的东西,并且这个地址是有意义的,避免产生不可预期的后果
1 | int main(){ |
可见效果: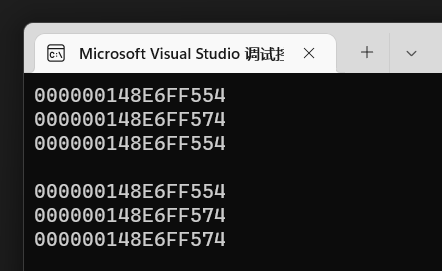
变量b的地址一开始时FF574,指针p在初始化的时候地址是变量a的地址,我们在后面修改了指针p的地址,使其得到变量b的地址。效果在第二次打印的时候可以看出。
可能有的人会有点懵,这里需要自己先理一下*和&的角度。
简单梳理完后,我们知道&也是属于单目运算符,那么指针是否也可以实现一些加减操作呢?
1 | int main(){ |
如果我们直接对指针–操作: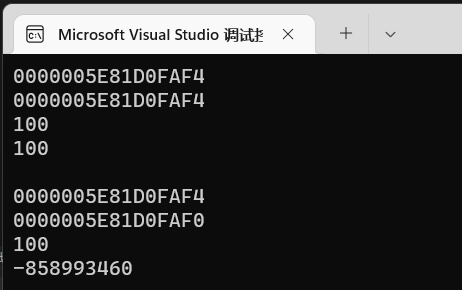
编译器其实也给出了警告:
- 这里能看出来p和a地址之间差了4?
- a的值能够正常输出,指针却不能显示正确的值了?
首先为什么会差了4,这跟类型占用空间有关。
为什么不能输出a的值了,原因在于,少了4之后的内存地址,我们没有给它赋值过,程序也不知道那一段数据有什么,万一前面的空间占了8字节,而我们只截取了一部分,那么数据也就是不完整的了。
所以指针要慎用,你要明确的知道你这个指针的操作是有什么目的。
至于为什么p--是修改地址而不是对a进行操作,这也跟运算符的优先级有关,我们将指针p用括号括起来看看效果:
1 | int main(){ |
可以看到,(*p)--之后,a的值同样发生了改变: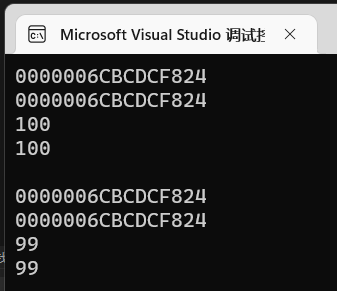
这也意味着(*p)-- == a--,能减自然也能加,能–在后,也能–放在前。
指针数组
基本定义
跟数组一样,在变量名前加个*,例如:
1 | int *pCh[10]; //代表声明了10个int类型的指针 |
在此之前,我们先验证一下正常的数组的内存地址是否是连续的:
1 | int ch[10] = { 1,2,3,4,5,6,7,8,9,10 }; |
可以看到: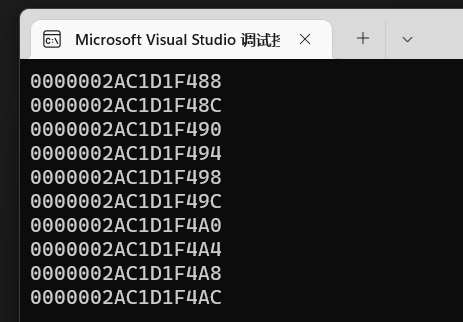
16进制,A=10,B=11。。。F=15
这个一维数组的内存地址也让我们很好理解了,上述对单个指针–操作的时候为什么地址少了4,原因离不开变量的类型。
二维数组以至于多维数组的地址也都是连续的。
指针大小
利用sizeof()同样可以测出指针的大小
1 | int main(){ |
结果是: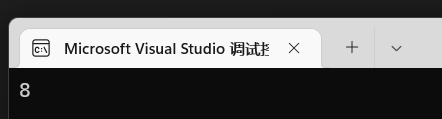
看到是8,很多人会想到可能跟变量类型有关。那如果是char类型的指针呢?
1 | int main(){ |
结果是: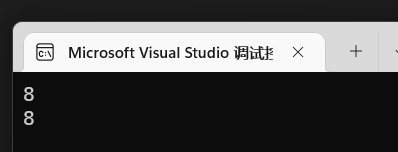
两者都是8,说明了一个问题,指针它声明的时候他自己其实也是个变量,是变量就需要占用内存空间。
tips: 默认vs2022 是使用x64编译,你可以尝试一下x86编译后。
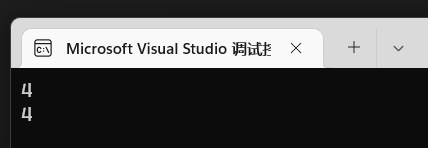
可以看到在x86下编译执行后,指针的占用空间变成4字节了,这其实跟操作系统位数有关:
操作系统位数的影响
32位的操作系统下,寻址范围是32位,也就是32bit,等于4byte。
64位的操作系统下,寻址能力是64位,也就是64bit,等于8byte。
这里先不扯寄存器和地址总线的问题,一旦深究,会发现和现实情况有所出入,目前先代入理解指针为什么一会占用4字节一会占用8字节。
我们在x86下打印指针p的地址看一看: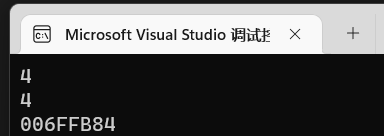
16进制两位等于一字节,这里有8位 / 2 = 4,也就是4字节。
转换成x64下再印呢?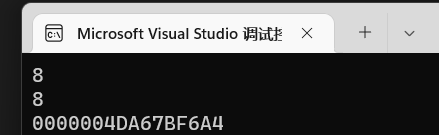
这里一共16位 / 2 = 8,也就是8字节。
为什么不打印char *指针的地址呢,首先我们要明白一个事,指针内存占用是4字节或者8字节了,但是char本身只占用一个字节的空间。那么将char类型的地址赋给char *就会产生一个问题,char*可以表示出char,但是你直接打印char *的时候,四字节只有一个字节是有明确含义的地址,就会导致乱码。
1 | int main(){ |
打印后可以很清楚的看到: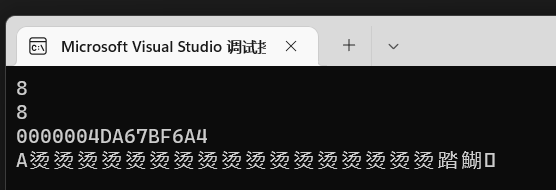
A是打印了,但是后面都是乱码。
然后回到上文:我们继续探讨指针
想必几个简单的案例,就能看出指针的强大之处。可是越强大就越不好掌握。
再往下看
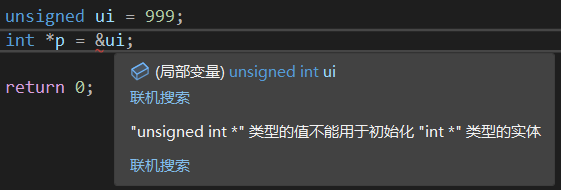
首先,不同类型隐式转换肯定不成功,那么我们就用强制转换
1 | unsigned ui = 999; |
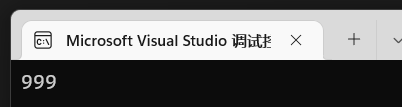
值都是正常的,我们说unsigned是无符号的意思,也就是说ui不能表示为负数
1 | *p = -1; |
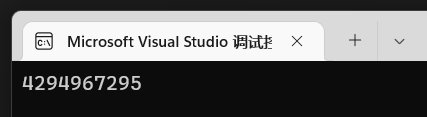
输出ui的时候发现,ui变得很大,这是因为变量都有固定的大小,四字节的时候,2^32次-1正好就是这个数。
如果使用更大类型或者更小类型去强转,则会发生不可预料的情况,因为ui默认只占了四字节,多了或少了系统读取的内存不一样了,内容也会各不相同。
但是我们再输出*p: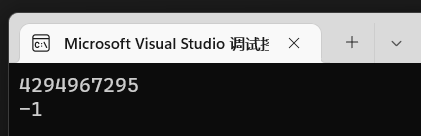
发现正常输出-1了,这是因为指针就是int类型,而ui却是unsigned。可想而知,计算机太单纯了,他单纯的表示二进制,符号位也是我们强加的,因此指针的类型不但在于它占用多少空间,更是为了让计算机怎么去处理这个指针的内容。
练习一下
1—
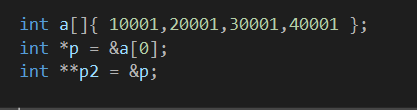
1 | int a[] {10001,20001,30001,40001}; |
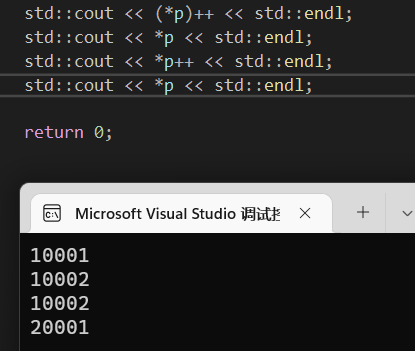
首先*p 目前是a[0]的地址,可以打印出10001。
()阔号的优先级更高,所以先在内存中读出10001,然后在进行++操作,故此(*p)++ = 10002,但是由于直接打印,++在右边,所以先输出10001,然后在自增。
而*p++呢,没有修改优先级,相当于地址+1,那么默认在p的地址上+4,为什么加4前面说过了,int类型占用四字节,地址自增,就是每次往后移动四字节【根据类型】。所以这里*p++的结果为20001。但是同理,++在右,先运算在自增。由于之前(*p)++了,所以这里的*p的值默认变成了10002,但是对于地址而言,移动四字节变成了a[1]:20001的地址。
这里不好理解的话,再解释一下,int类型的指针默认占用4字节,x86的情况下,当计算机去读取的时候肯定也是四个字节来读,那么指针+1,他肯定是要按照它本身地址+类型占用空间,通俗的话说这个1就是它自己
+1 就使得p的地址移动到了20001的地址,那么从a[0]开始+2,p就会移动到30001的地址
当然这个可能看上去不直观,那么修改一下先输出数组所有元素的地址
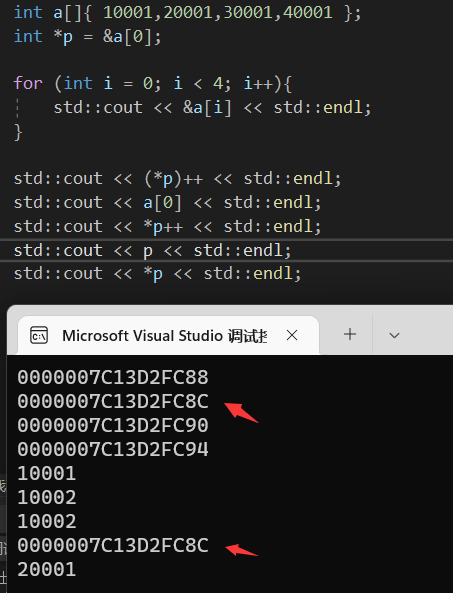
然后的然后我们就可以开始套娃了:
是变量都会有占用空间,都会有内存地址,那么指针变量也不例外
1 | std::cout << &p << std::endl; |
就可以输出指针的地址了,以上述的题打样:
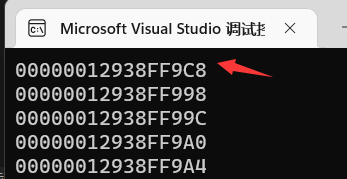
应该是能清楚看到p的地址比数组成员都要大,当然这是因为数组先声明,在内存中肯定早点申请了空间。
2—
回归正题,*p 能操作同类型的地址,那么如何操作*p的地址呢。
有意思的衍生出了二级指针
1 | int **p2; |
需要注意的是:
- 二级指针只能指向一级指针的地址,不能指向单纯的变量地址
- 不用尝试&&去获取变量的地址,无效套娃

1 | std::cout << p << std::endl; |
输出p的地址和*p2的地址是相同的: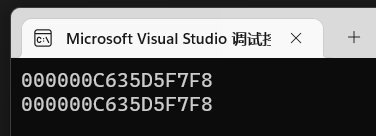
那么**p2的值就是*p代表的值了: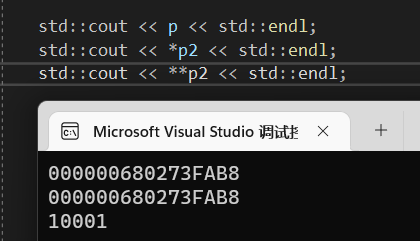
反复提醒:变量存在于局部时,每次运行分配的地址与之前不同。
如果你想要整一个int ***p3和int ****p4,ok都没关系,都可以操作,只是相应的,要注意高级别的指针只能指向低一级的地址。【多维数组与多级指针息息相关】
3—
补充一个东西,const 是限定一个变量为常量,即初始化后不可以修改。
1 | const int a = 100; |
所以指针也要变成const
1 | const int a = 100; |
const是限定了一个常量。那么常量指针还能从而修改值吗?
答案是不能: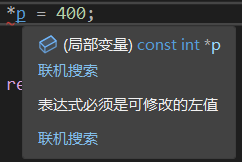
但是,常量指针可以重新指向别的常量:
const int *p 的当const在前的时候即限定了这个指针不能修改地址里面的值,只能换地址
随记表面 const能放后面。int *const p
脑袋肯定晕乎乎了。。。不过const在前时指针称为常量指针,const在后时称为指针常量
先看指针常量:
当const出现在变量名前面的时候,就已经是常量了,说明了这个指针初始化后肯定是不能修改地址了。
不过还是能修改初始化时地址的变量。
1 | int a = 100; |
还没完!!!!!!
const前后都放过了,那如果前后都存在呢?
1 | const int a = 100; |
当出现两个const的时候,称之为指向常量的常量指针,也就说当这个指针初始化后,既不可以修改指向的内存地址,也不可以修改内存地址上的数据。
说人话就是这种限定完之后啥都不能改了。
强制转换
强制转换用到的地方也不少,在两个类型不相同的变量传递之间,隐式转换不起作用那么就需要我们手动强制转换,指针也不例外。
1 | const int a = 1000; |
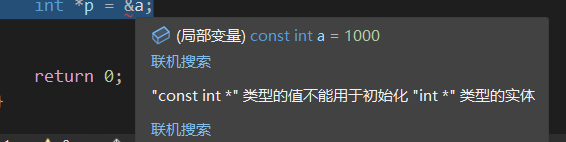
将其修改为:
1 | const int a = 1000; |
然后印证指针p指向的是a的地址:std::cout << *p << std::endl;
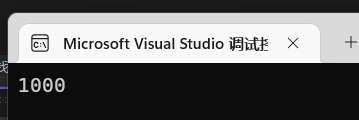
打印出来的也是1000,说明没啥问题。
如果我们修改指针的值呢,发现也的确可以修改:
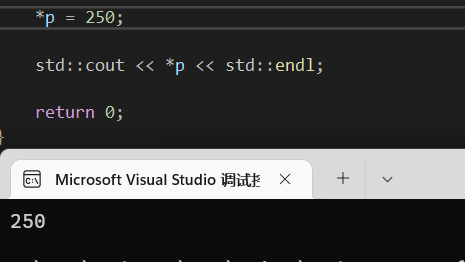
但是有个问题了,a是什么,a是一个常量,它的值会改变吗?
打上断点转到反汇编浅看一下:
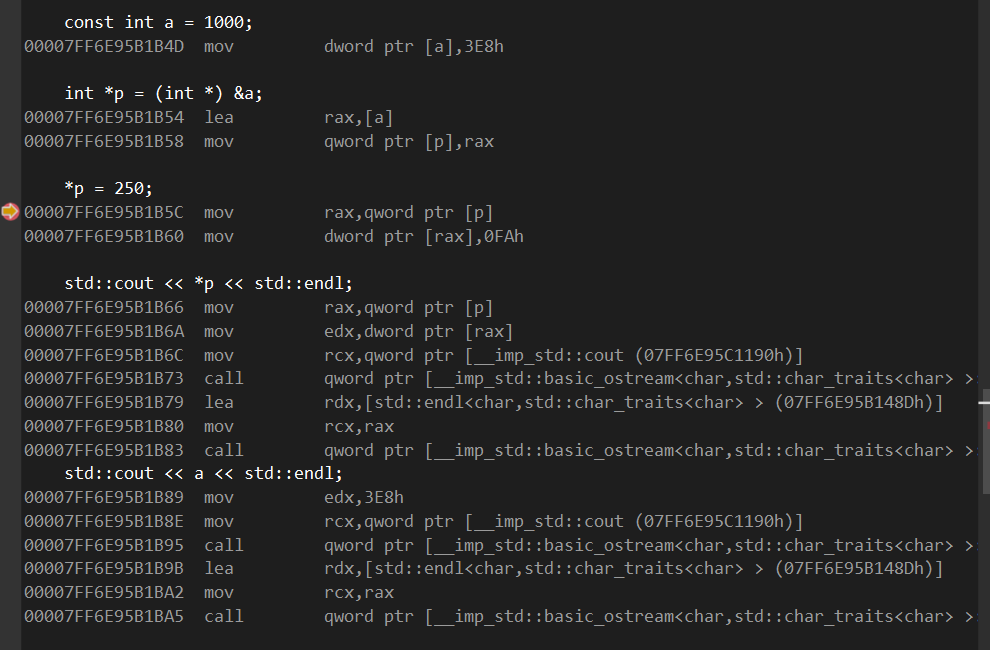
- 在初始化a的时候,将[3E8h]转成十进制就是1000 mov到 a的地址上。
- 然后将a强转给指针p的时候,编译器先把a的地址存到rax寄存器上
- *p=250的时候,又把p的地址 mov到 rax寄存器上,然后将[0FAh]这个十六进制转换成十进制就是250 mov到rax寄存器的地址上。
- 然后打印*p的时候,又先将指针p的地址mov到rax上,在将rax的地址mov到rdx上;打印a的时候则是直接将[3E8h] 1000的值 mov到rdx上。
虽然对于汇编知识较为欠缺,但是凭大概看法就是,编译器是修改了*p的值,但是他也记住了a本身的值一样,就是类似于宏定义,这样不论什么时候调用a,他都直接以3E8h的值进行传递。
结语
指针还是很神奇的东西。。以后不少地方还会用到,得好好摸索摸索。