pointerArray
前言
分析一下编译器vs2022对数组的访问操作。
正文
先参照一下视频的分析
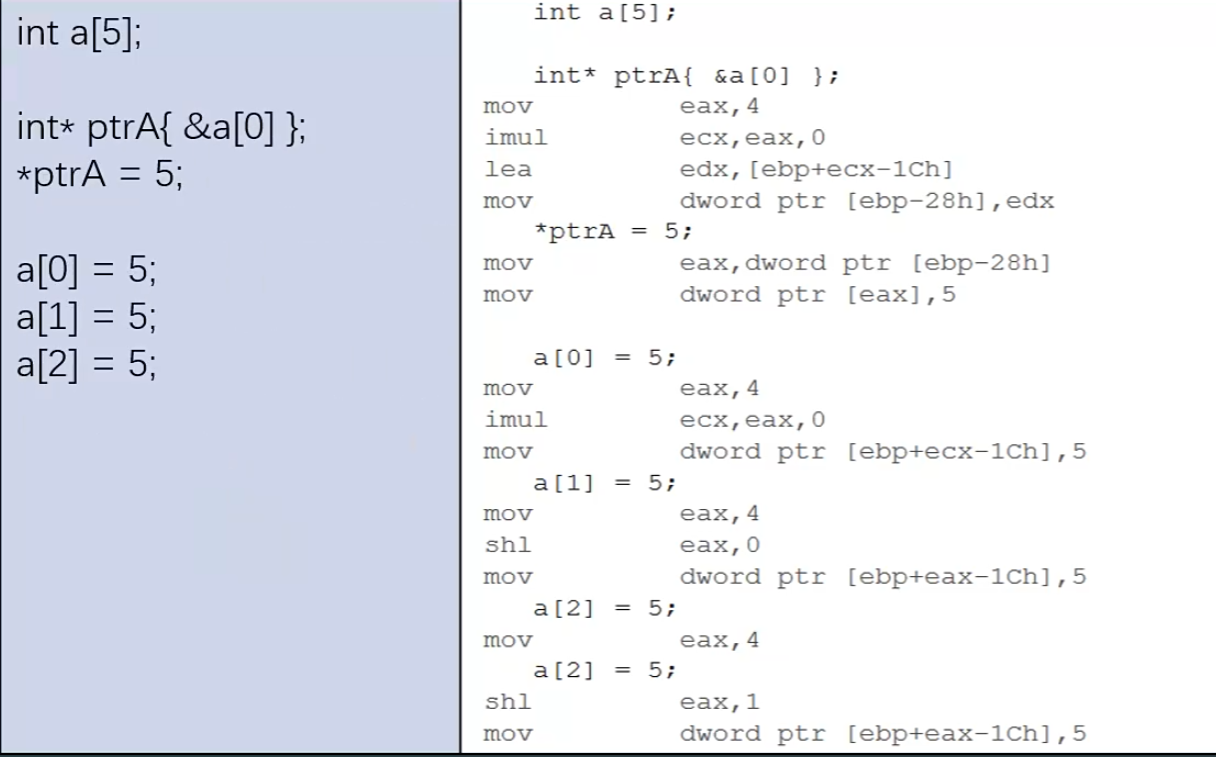
汇编这玩意,看着看着倒是顺眼了,前提是简单的操作。
- mov eax,4 就是类似于eax=4
- imul ecx,eax,0 是 eax*0之后赋值给ecx,不过都乘以0了,ecx也就是0了
- lea edx,[ebp+ecx-1Ch] ecx是0在上一步有说明了,就剩ebp-1Ch的地址传递给edx
- mov dword ptr [ebp-28h],edx 这一步就是将[ebp-28h]的这段空间写入edx,也就是[ebp-1Ch]
- mov eax,dword ptr [ebp-28h] ,这里[ebp-28h]已经写入了之前说的edx的值[ebp-1Ch],相当于eax=edx了
- mov dword ptr [eax],5 ,因为之前也说了eax=edx,所以这里给eax=5,就是变相的给edx=5
然后回头看,能说什么说明?说明edx的那段内存地址是属于a[0]的,而[ebp-28h]的那段空间就是指针占用的部分,换种写法就是[ebp-28h] = [ebp-1Ch] / 也就是int *ptrA = &a[0];
不信话看a[0] = 5这段反汇编
- mov eax,4 也就是eax=4
- imul ecx,eax,0 也就是ecx = exa * 0;
- mov dword ptr [ebp+ecx-1Ch],5 这一步将5传递到[ebp+ecx-1Ch]上,ecx=0了,也就是[ebp-1Ch] = 5,那么你会发现,在上述分析的时候,int *p = &ch[0],也出现了[ebp-1Ch],可想而知,[ebp-1Ch] 他就是a[0]占用的地址。
在看a[1] = 5
- mov eax,4
- shl eax,0 ,shl是左位移操作,相当于eax << 0, 那么向左位移的时候说过,相当于eax * 2^n,这里n=0,所以eax * 2^0 ,也就是eax*1,4*1,这里eax还是=4;//正常情况下左位移一位相当于原数乘以二
- mov dword ptr [ebp+eax-1Ch],5 这里有意思了,虽然看似差不多,但是这个时候eax的值已经是4了,所以ch[1]的地址就是[ebp+4-1Ch]。同理这句话就是[ebp+4-1Ch] = 5;
最后a[2] = 5
- mov eax,4 ,eax=4
- shl eax,1 ,eax << 1, eax * 2^1,也就是eax = 8
- mov dword ptr [ebp+eax-1Ch] , 也就是[ebp+8-1Ch] = 5; 那么a[2]的地址也就是[ebp+8-1Ch]
往后推a[3]的地址也就是[ebp+12-1Ch],a[4] = [ebp+16-1Ch]。
所以说数组的地址,都是基于首地址进行一个偏移量,这个偏移量根据类型得出,首地址也就是a[0]
看a[1]的时候,[1]就是代表了要进行的偏移量,1*4,那么怎么获取首地址呢,就要靠前面那个a,所以能得出a == &a[0]的结论。
实际测试效果一致
1 | std::cout << a << std::endl; |
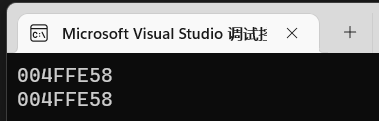
看到地址确实是一样的。那么论证a == &a[0]是成立的。也就是说当指针指向一个数组首地址的时候,可以直接int *p = a。
1 | int main(){ |
发现他俩得值都是一样的:
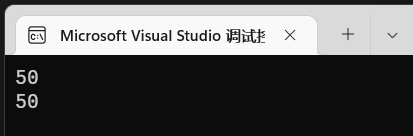
那么反推过来,因为看过了反汇编,发现数组其实就是指针偏移过来的产物。
除了特定情况下:比如sizeof的时候,a代表的才是一整个数组,这点我们在学习求数组长度的时候就知道,sizeof(ch)/sizeof(ch[0]);但是我们sizeof(p)他只能是4,64位是8。因为本质上指针就是指针,数组是经过包装的。
多维数组
多维数组声明的时候就看有几个[],
1 | int ch[10]; |
但是,数组是一片连续的空间,那么多维,就只是人用逻辑结构抽象出来的产物。为什么这么说呢,往下看
1 | int ch[10]; |
2*5=10,5*2=10,那么物理上,一维和多维可以说是没有什么区别,就是抽象多了一层结构,方便人去阅读和理解。
为了更好理解,继续用代码测试:
1 |
|
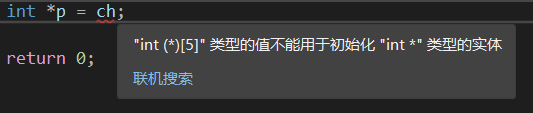
会看到提示类型转换有问题,那么老样子强转一波:int *p = (int *)ch;
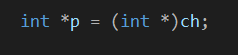 没问题,那就继续操作。
没问题,那就继续操作。
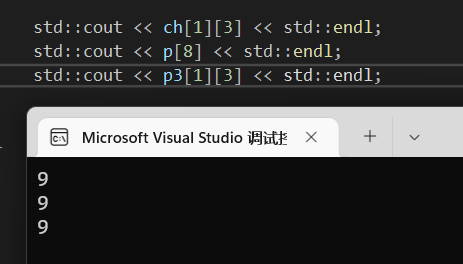
正常情况下访问ch的第九个元素要通过ch[1][3]获取。那我们是否能用p[8]直接访问。
1 | std::cout << ch[1][3] << std::endl; |
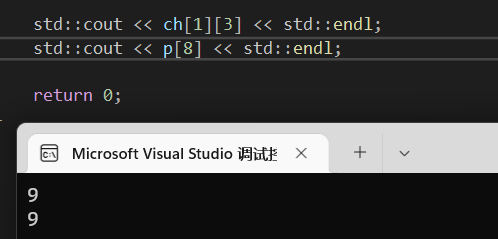
发现能正常输出啊,这就恰好论证了我们之前说的在底层中,多维实际上跟一维没有差别。
但是不是说多维就没用,不然这种逻辑结构就没有存在的意义了,这里只是探究本质。多维在很多地方还是很有用的,几行几列是人最习惯的东西。
想要指针实现多维的效果也是可以的:
1 | int *p2[5] = ch; //不合法,因为这种写法是声明了五个int类型的指针,通常称为指针数组 |
发现结果都一样,说明逻辑结构存在了。
然后我们再看看它们的大小: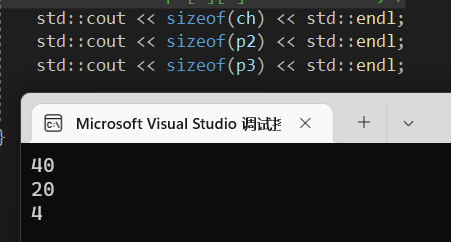
发现指针数组的区别在于他是变量类型*[]的数字,而数组指针仍然是一个指针的大小。
再看看指针数组+1和数组指针+1的区别:
数组指针+1的时候: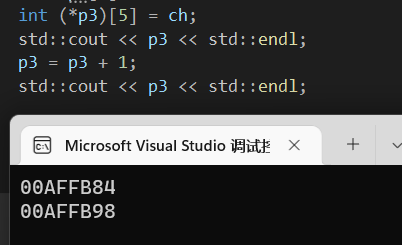
它们之间相差20,这个20怎么来的,就是变量类型乘以[]的数字得来的,数组指针这种写法会造成特殊的逻辑,*p2看作行,[5]看作列,那么p2每加一个1,他的步长就变成了5。所以不是我们之前说的指针正常+1,就是偏移一个他的变量类型。
指针数组我们说了定义就是几个int类型的指针,它每次加一,步长就为变量类型的大小。
这也是一个误区,容易弄混淆的地方,所以要特别注意数组指针和指针数组的使用方式。
然后就是之前说过的一维数组的时候,ch[0]可以表示为数组的首地址,ch同样可以,因为参照的是ch[1~n]都要参照ch作为首地址进行偏移,那么二维数组呢?或者说多维数组,是不是也有相同的操作。
可以尝试一下,直接打印各自的首地址:
1 | std::cout << *p3[0] << std::endl; |
发现结果是一样的: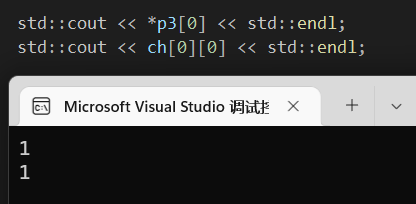
二者的地址也是一样的: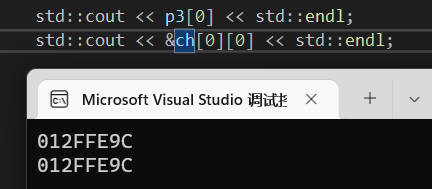
甚至说俩都+1,往后偏移一位,结果也是一样的: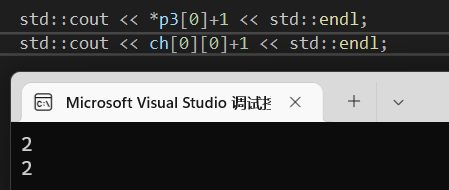
所以ch[0][0] 也是要参照前面的ch[0]来偏移获取,故此ch[0] == ch[0][0]也得到了论证。
试试看自己机子反汇编后的
然后自己先随便写一段:
1 | int main(){ |
然后老样子随便在一句代码上打个断点进行反汇编:
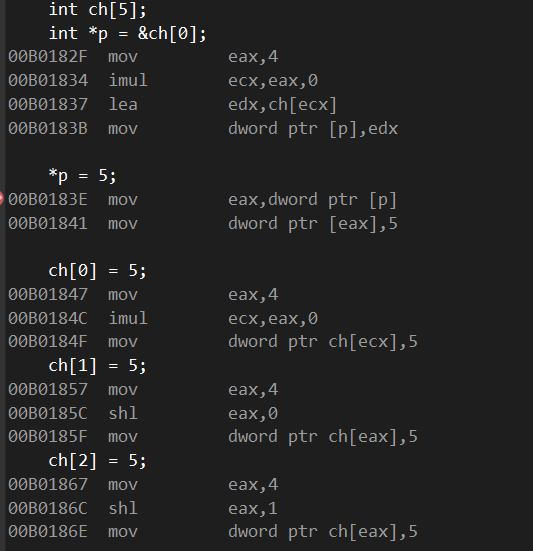
不知道是不是编译器的问题,视频用的2019,我用的2022。x86都是x86,但是在每个mov上操作的不太一样。
像视频教学的时候最后赋值是mov dword ptr [ebp+eax-1Ch],5。通过这样的写法能直观的看出规律。和计算出位置。
而我自己这个2022反汇编出来的,最后赋值的时候却是mov dword ptr ch[eax],5。就感觉有点突兀了。
摘自ch[1]=5
- eax,4 //eax = 4 没啥问题
- shl eax,0 //eax << 0, eax = 4
- mov dword ptr ch[eax],5 //但是这个ch[4] = 5就不太现实啊
怎么说这里eax也应该是1才对,除非你说要除以变量类型,或者说先计算出指针ch的地址在+上eax作为偏移量,这样换算也行。
后面听群友说要关闭显示符号名
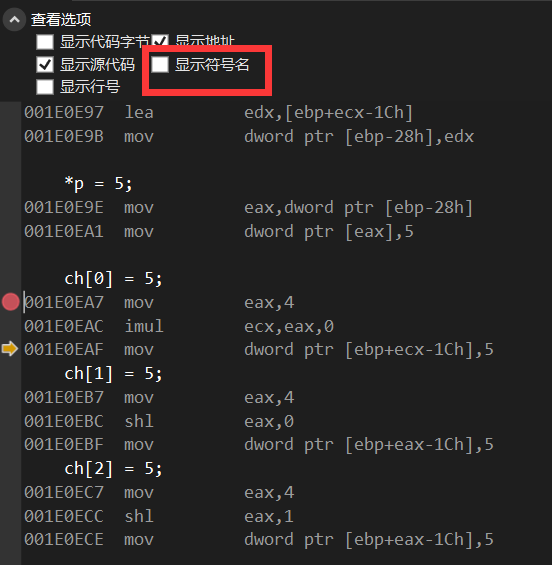
看到雀食变成ebp的形式了
结语
看起来觉得没啥东西,学起来又绕来绕去,学完了或多或少没记全。。。多用用或许还能避避坑,反正用到了再回头看看。